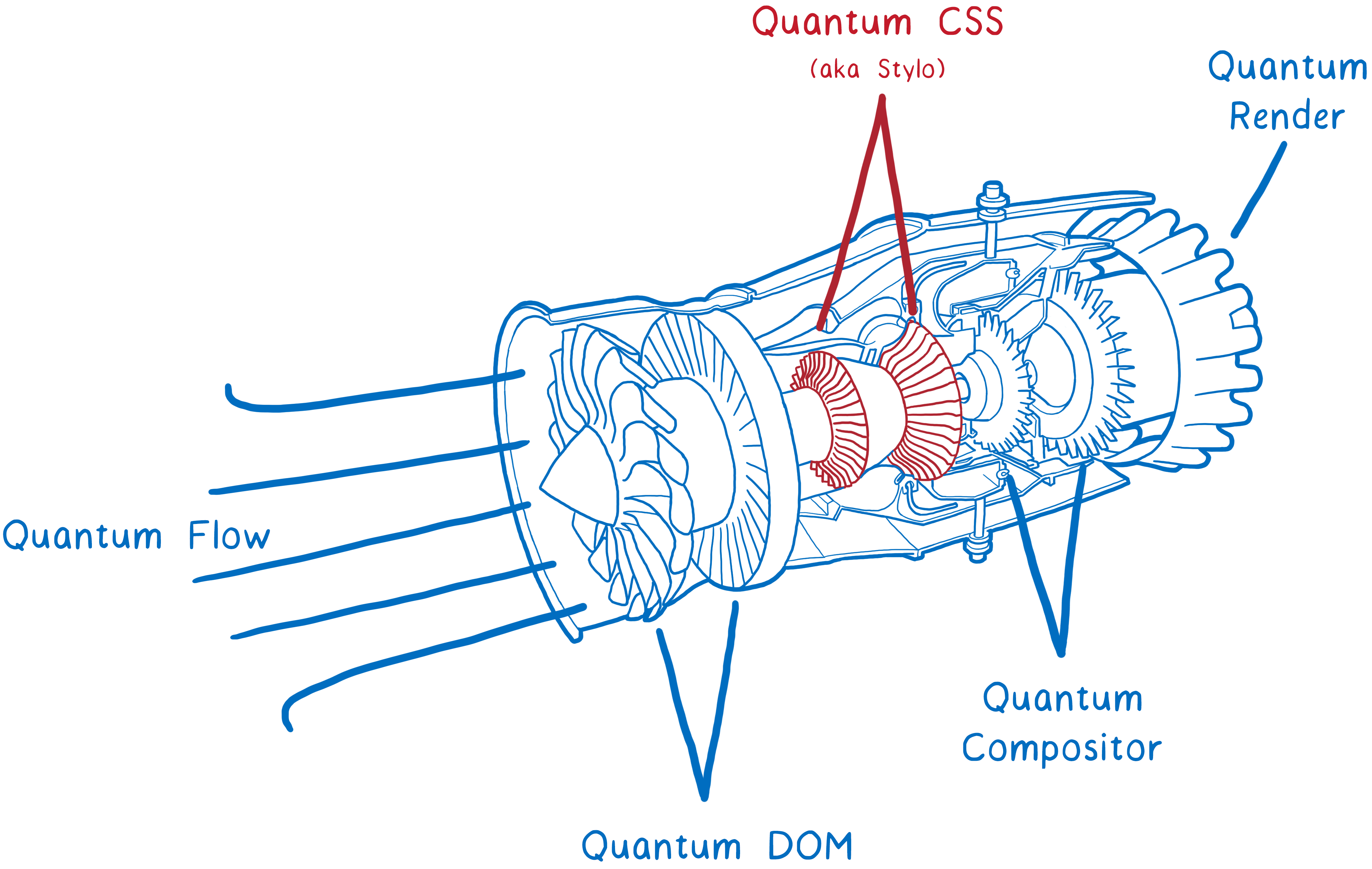
Et le premier composant majeur de Servo – un nouveau moteur CSS appelé Quantum CSS (connu auparavant sous le nom de Stylo) – est maintenant en cours de test dans la version Nightly de Firefox. Vous pouvez vérifier que le nouveau moteur est activé chez vous : dans la page about:config, vérifiez que le paramètre layout.css.servo.enabled est à true.
Ce nouveau moteur rassemble les innovations de l’état de l’art de quatre navigateurs web différents pour créer un super moteur CSS.

Il profite des matériels modernes en parallélisant le travail à travers tous les cœurs de votre machine. Il peut donc fonctionner deux, quatre ou même dix-huit fois plus rapidement.
En plus de cette amélioration, il combine l’état de l’art des optimisations utilisées par les autres navigateurs web. Ainsi, même si la parallélisation n’est pas utilisée, il s’agira toujours d’un moteur CSS rapide.

Mais que fait un moteur CSS ? Commençons par inspecter le moteur CSS et comment il s’insère dans le reste du navigateur. Ensuite, nous verrons comment Quantum CSS fait pour tout accélérer.
Que fait un moteur CSS ?
Le moteur CSS est une partie du moteur de rendu du navigateur. Le moteur de rendu prend le code HTML et les fichiers CSS d’un site web et les transforme en pixels sur l’écran.
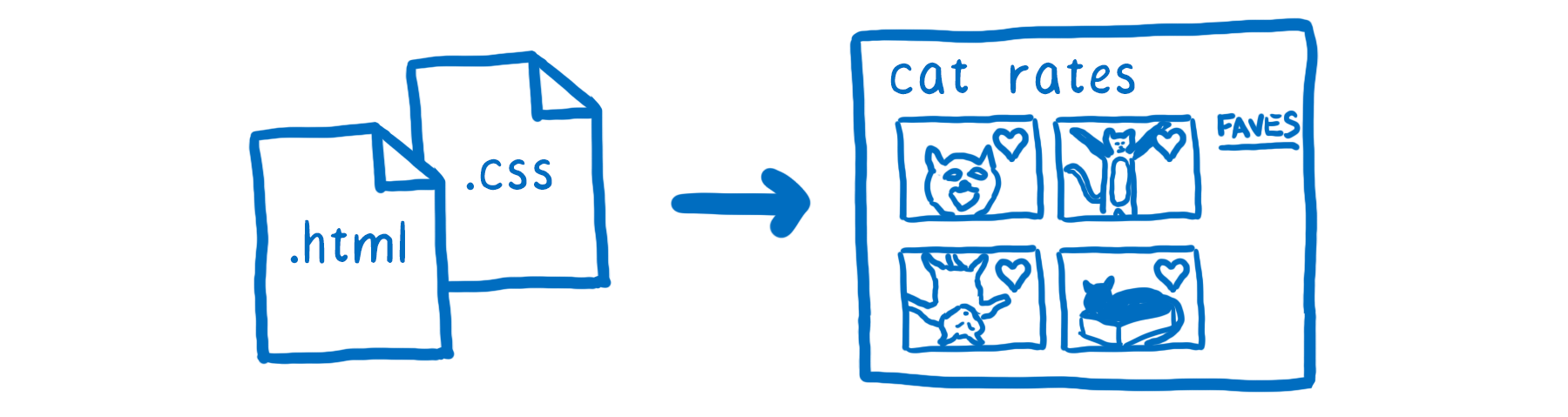
Chaque navigateur web a son propre moteur de rendu. Dans Chrome, il s’appelle Blink. Dans Edge, c’est EdgeHTML. Dans Safari, il s’agit de Webkit. Et dans Firefox, il s’appelle Gecko.
Pour passer des fichiers aux pixels, tous ces moteurs de rendu font essentiellement les mêmes choses :
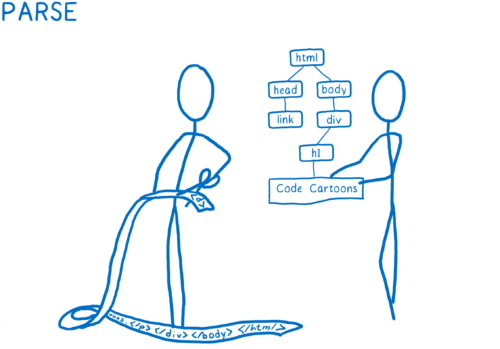
- Analyser les fichiers et les transformer en objets que le navigateur peut comprendre, dont le DOM. À cette étape, le DOM connaît déjà toute la structure de la page. Il sait tout sur les relations parents-enfants entre les éléments. Par contre, il ne connaît pas l’aspect visuel de chacun de ces éléments.
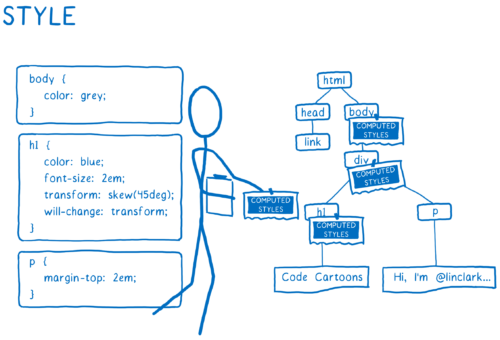
- Comprendre comment les éléments devraient apparaître. Pour chaque nœud DOM, le moteur CSS recherche les règles CSS à appliquer. Ensuite, il retrouve la valeur de chacune des propriétés CSS pour ce nœud DOM.
- Mesurer les dimensions pour chaque nœud et leur emplacement sur l’écran. Des boîtes sont créées pour chaque chose qui peut être affichée à l’écran. Les boîtes ne représentent pas seulement les nœuds DOM… vous avez aussi des boîtes pour des choses à l’intérieur des nœuds DOM, comme des lignes de texte.
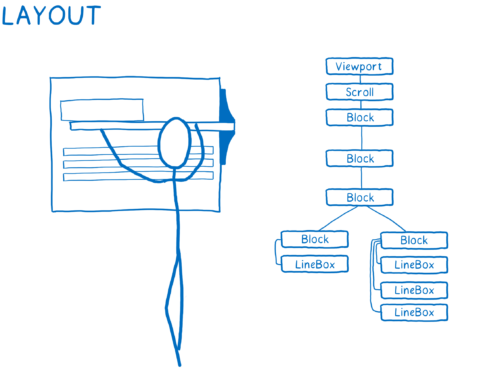
- Dessiner les différentes boîtes. Cela peut demander de nombreux calques. Je me représente cela comme les anciennes animations peintes à la main, avec différents papiers calques superposés comme une peau d’oignon. Cela permet de modifier juste un calque sans avoir à tout redessiner.
- Prendre ces différents calques, appliquer les propriétés de composition – comme les transformations – et les changer en image. C’est essentiellement comme prendre une photo des calques posés les uns sur les autres. Cette image est ensuite rendue sur l’écran.


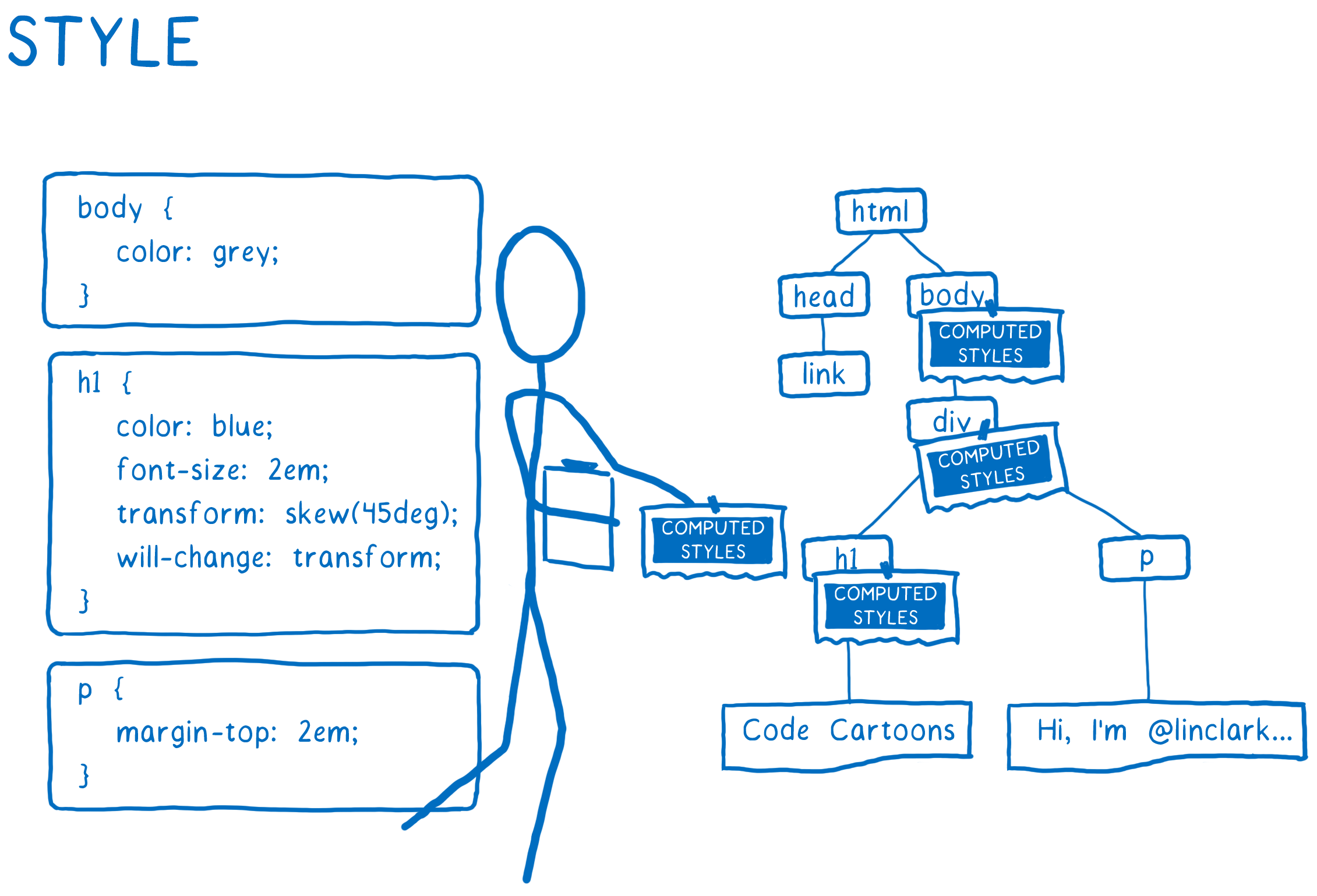

Ainsi, quand il commence à calculer les styles, le moteur CSS a deux outils à disposition :
- un arbre DOM ;
- une liste de règles de style.
Il parcourt tous les nœuds DOM, un par un, et pour chaque nœud il retrouve les styles associés. Durant ce processus, il donne au nœud DOM une valeur pour toutes les propriétés CSS, même si les feuilles de style ne déclarent pas de valeur pour certaines propriétés.
Je me l’imagine comme une personne qui est face à un formulaire et le remplit. Il a besoin de remplir un formulaire pour chacun des nœuds DOM. Et pour chacune des questions, il doit avoir une réponse.

Pour le remplir, le moteur CSS à besoin de faire deux choses :
- Trouver quelles règles s’appliquent au nœud — c’est-à-dire faire correspondre les sélecteurs CSS aux nœuds DOM ;
- Remplir toutes les valeurs manquantes avec les valeurs du parent ou une valeur par défaut – c’est ce qu’on appelle la cascade.
Faire correspondre les sélecteurs CSS aux nœuds DOM
Durant cette étape, nous allons ajouter chaque règle qui correspond au nœud DOM dans une liste. Comme plusieurs règles peuvent correspondre, il pourrait y avoir plusieurs déclarations de valeur pour une même propriété.

En plus des règles déclarées par le code du site, le navigateur ajoute lui-même certains CSS par défaut (appelés feuilles de style de l’agent de l’utilisateur). Comment le moteur CSS peut-il déterminer la bonne valeur ?
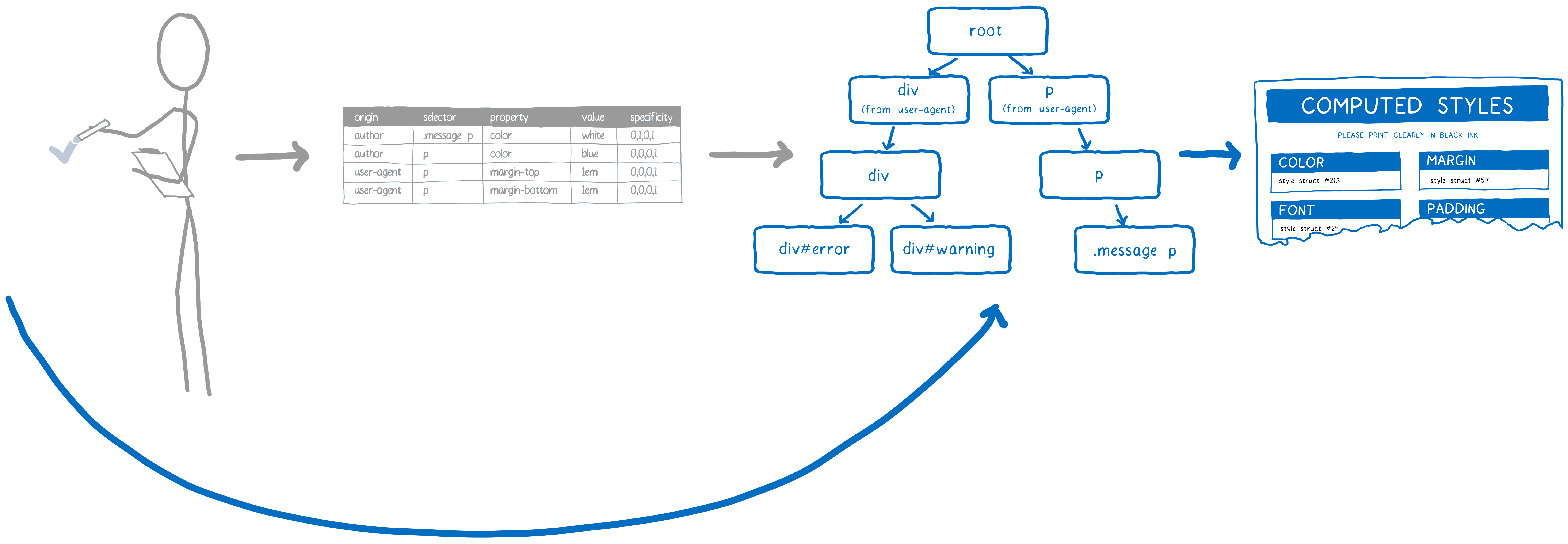
C’est ici que le principe de la spécificité des déclarations CSS intervient. Le moteur CSS crée en gros une feuille de calcul avec pour chaque ligne une déclaration CSS. Ensuite, il ordonne les lignes en fonction des différentes colonnes.
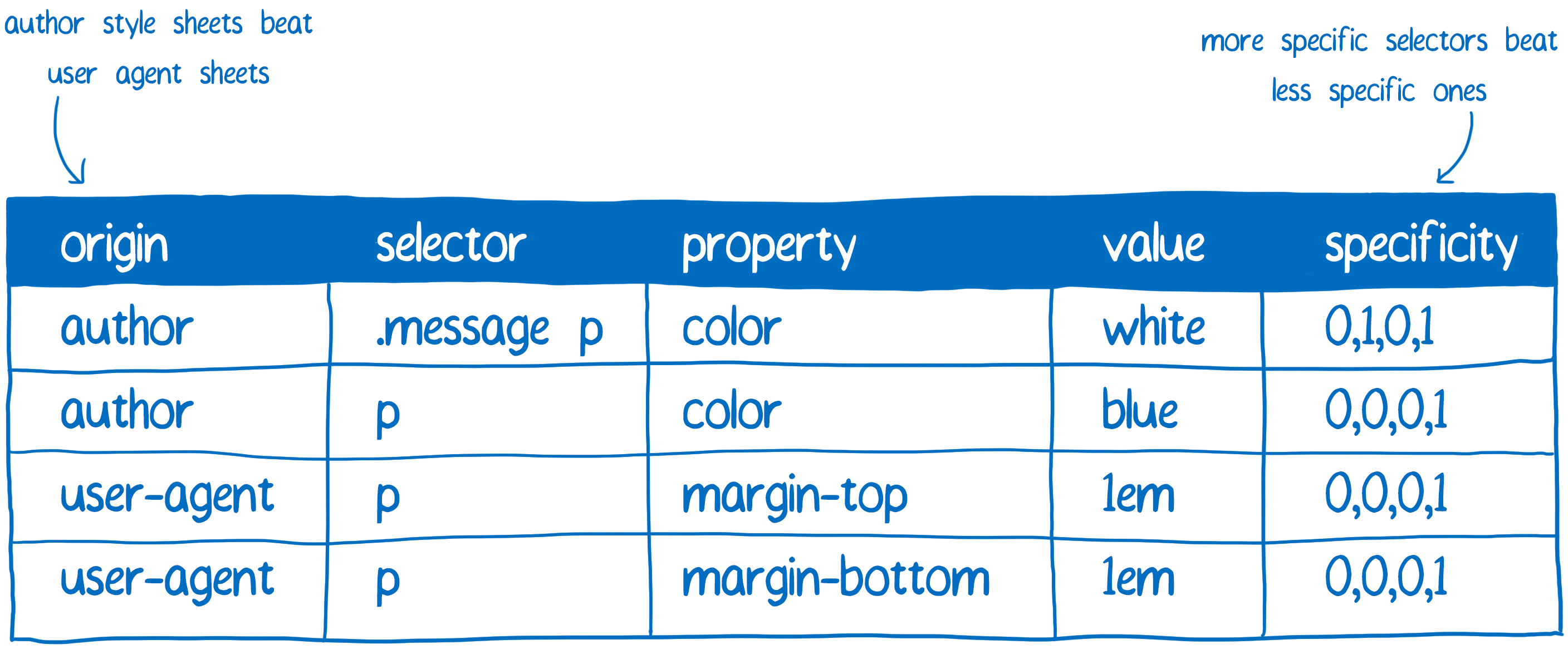
La règle CSS définie avec la plus grande spécificité gagne. Ainsi depuis cette feuille de calcul, le moteur CSS est capable de remplir les valeurs dans le formulaire. Pour l’instant, il ne remplit que les valeurs déclarées explicitement par des règles du code CSS du site.

Pour le reste, il va devoir utiliser la cascade.
La cascade
Le principe de la cascade rend le code CSS plus facile à écrire et maintenir. Grâce à la cascade, vous pouvez paramétrer la propriété color une fois sur le corps de la page body et vous savez que le texte des éléments p, span et li utilisera la même couleur (à moins d’avoir une règle plus spécifique qui surpassera cette valeur).
Pour arriver à ce résultat, le moteur CSS regarde tous les blancs qui restent dans le formulaire. Si une propriété hérite par défaut la valeur de l’élément parent, alors le moteur CSS remonte l’arbre DOM et regarde si le parent a une valeur. Si aucune valeur n’est déclarée pour le parent ou si une propriété n’hérite pas, il utilise la valeur par défaut.

Maintenant tous les styles ont été calculés pour ce nœud DOM.
Quelques précisions : le partage des structures de styles
Le formulaire que je vous ai montré est une simplification. Le standard CSS a des centaines de propriétés. Si le moteur CSS tenait pour chaque nœud DOM la liste de chaque propriété avec une valeur, il serait rapidement à court de mémoire.
Ainsi, au lieu de tenir de tels formulaires, les moteurs utilisent généralement ce qu’on appelle le partage des structures de styles. Ils enregistrent les données qui vont habituellement ensemble (comme toutes les propriétés de police d’écriture) dans un même objet appelé structure de styles. Ensuite, plutôt que d’avoir toutes les propriétés dans un même objet pour un nœud, l’objet contenant le style calculé du nœud est un ensemble de pointeurs. Pour chaque catégorie de propriétés, il y a un pointeur vers une structure de styles qui a les bonnes valeurs pour ce nœud DOM.
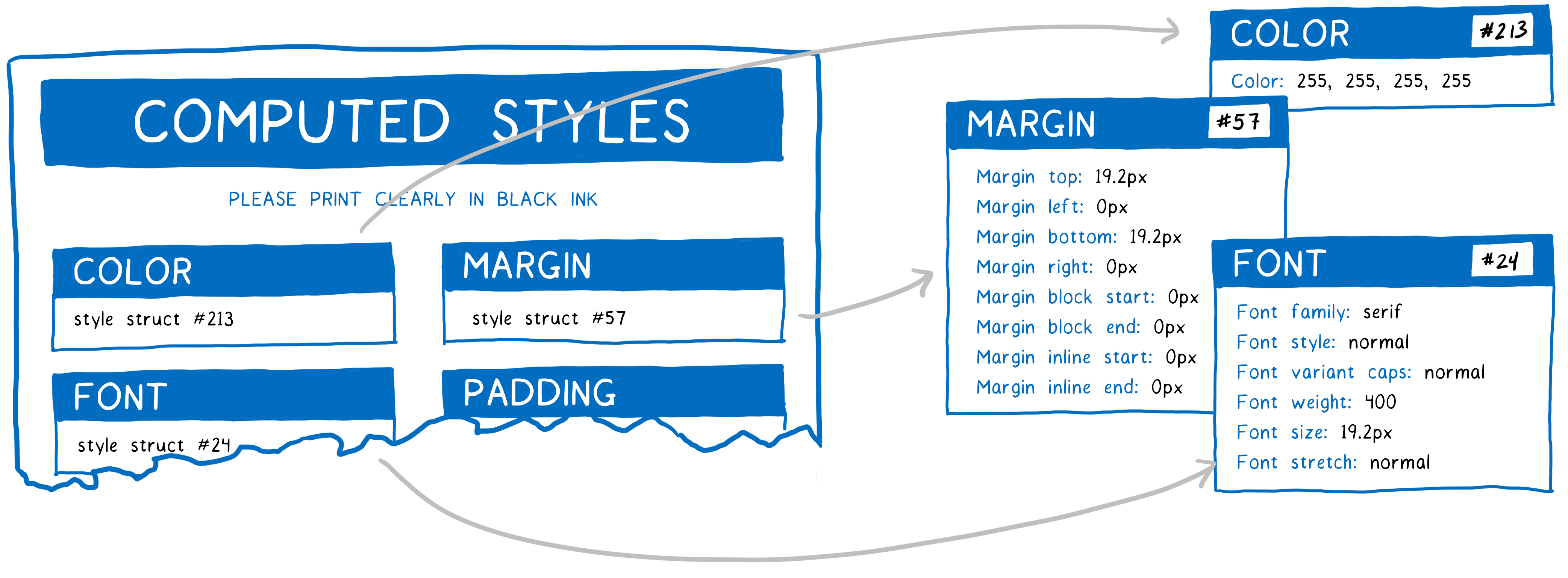
Cette technique permet à la fois de réduire l’espace mémoire et le temps de traitement nécessaire. Tous les nœuds qui ont des propriétés proches (comme les jumeaux) peuvent simplement pointer vers les mêmes structures pour les propriétés partagées. Et comme beaucoup de propriétés sont héritées, un ancêtre peut partager une structure avec tous ses descendants qui n’ont pas de déclaration de valeur plus spécifique.
Maintenant, comment peut-on faire tout cela rapidement ?
Voici à quoi ressemblent les calculs de styles si vous ne les avez pas optimisés.

Il y a beaucoup de travail qui se passe ici. Et pas seulement au premier chargement de la page. Le travail doit être refait encore et encore tant que l’utilisateur interagit avec la page, en passant la souris par-dessus des éléments (hover) ou en modifiant le DOM, déclenchant à nouveau le calcul des styles.
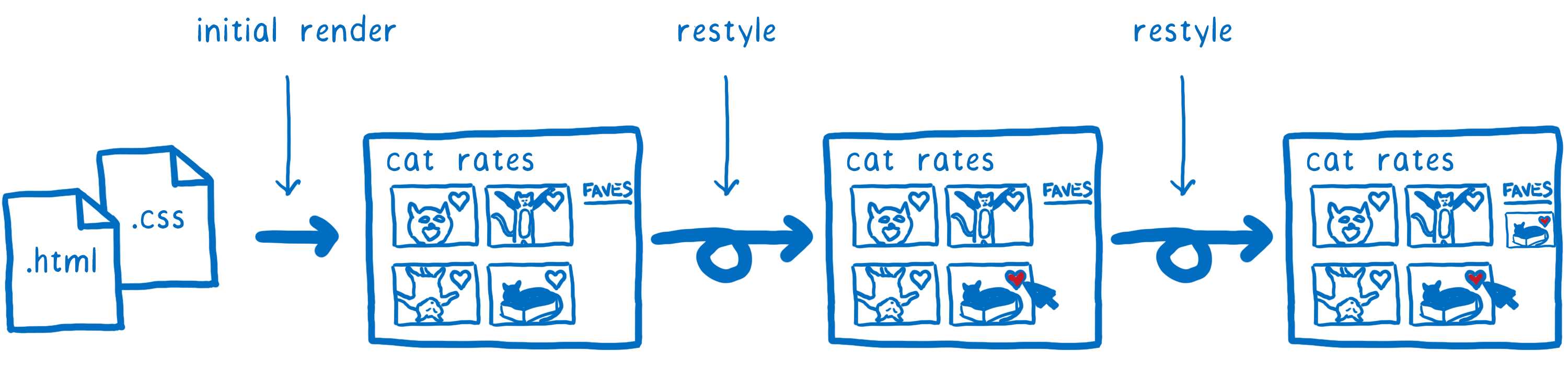
Ainsi, le calcul des styles CSS est un très bon candidat pour l’optimisation… et les navigateurs ont testé différentes stratégies pour l’optimiser durant ces 20 dernières années. Ce que Quantum CSS fait est de prendre le meilleur des stratégies des différents moteurs, de les combiner et de créer un nouveau moteur très rapide.
Examinons donc en détails comment faire fonctionner ensemble ces stratégies.
Tout faire en parallèle
Le projet Servo (d’où vient le moteur Quantum CSS) est un navigateur expérimental qui essaie de paralléliser toutes les différentes parties de la création de rendu d’une page web. Qu’est-ce que cela signifie ?
Un ordinateur ressemble à un cerveau. Il y a une partie qui pense (l’ALU). Très proche de celle-ci il y a une mémoire à court terme (les registres). Ces parties rassemblées forment le processeur (CPU). Ensuite, il y a la mémoire à long terme, la RAM.
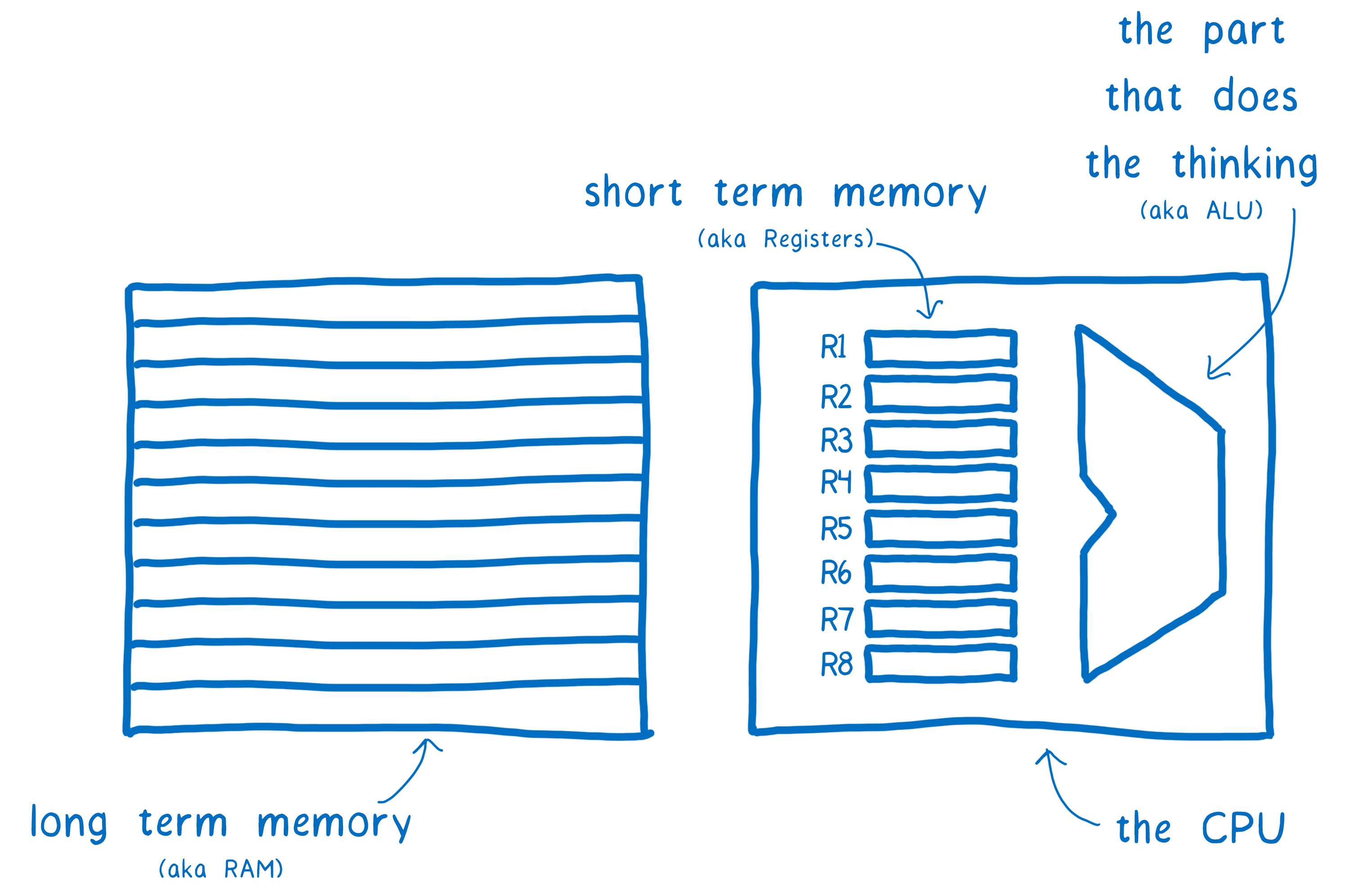
Les premiers ordinateurs ne pouvaient penser qu’à une chose à la fois en utilisant ce CPU. Mais ces dernières années, les CPU ont évolué pour avoir plusieurs ALU et registres, regroupés en cœurs. C’est-à-dire que le CPU peut penser à plusieurs choses en même temps – en parallèle.
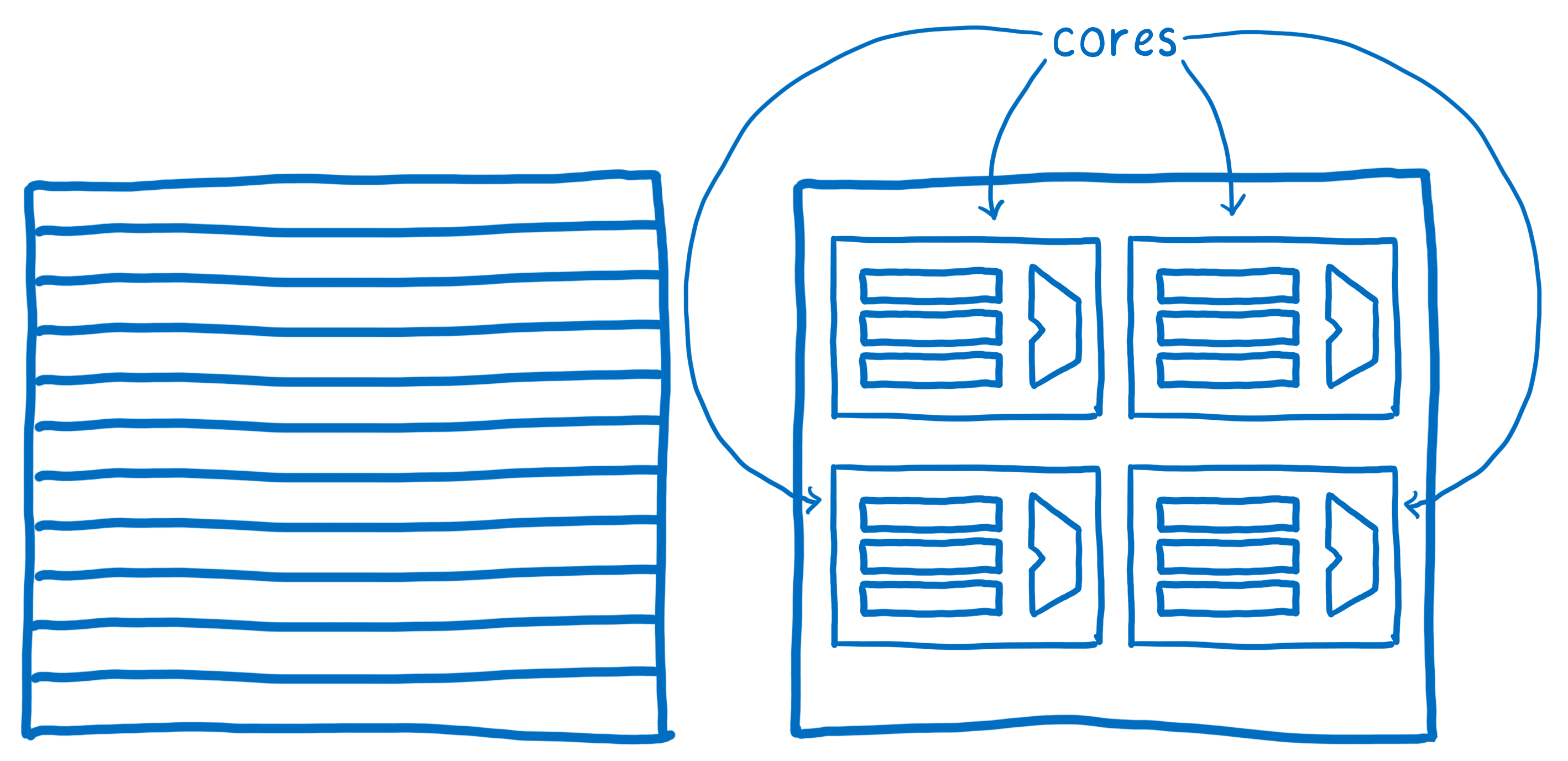
Quantum CSS utilise cette fonctionnalité récente sur les ordinateurs en partageant le calcul des styles pour les différents nœuds DOM à travers les différents cœurs.
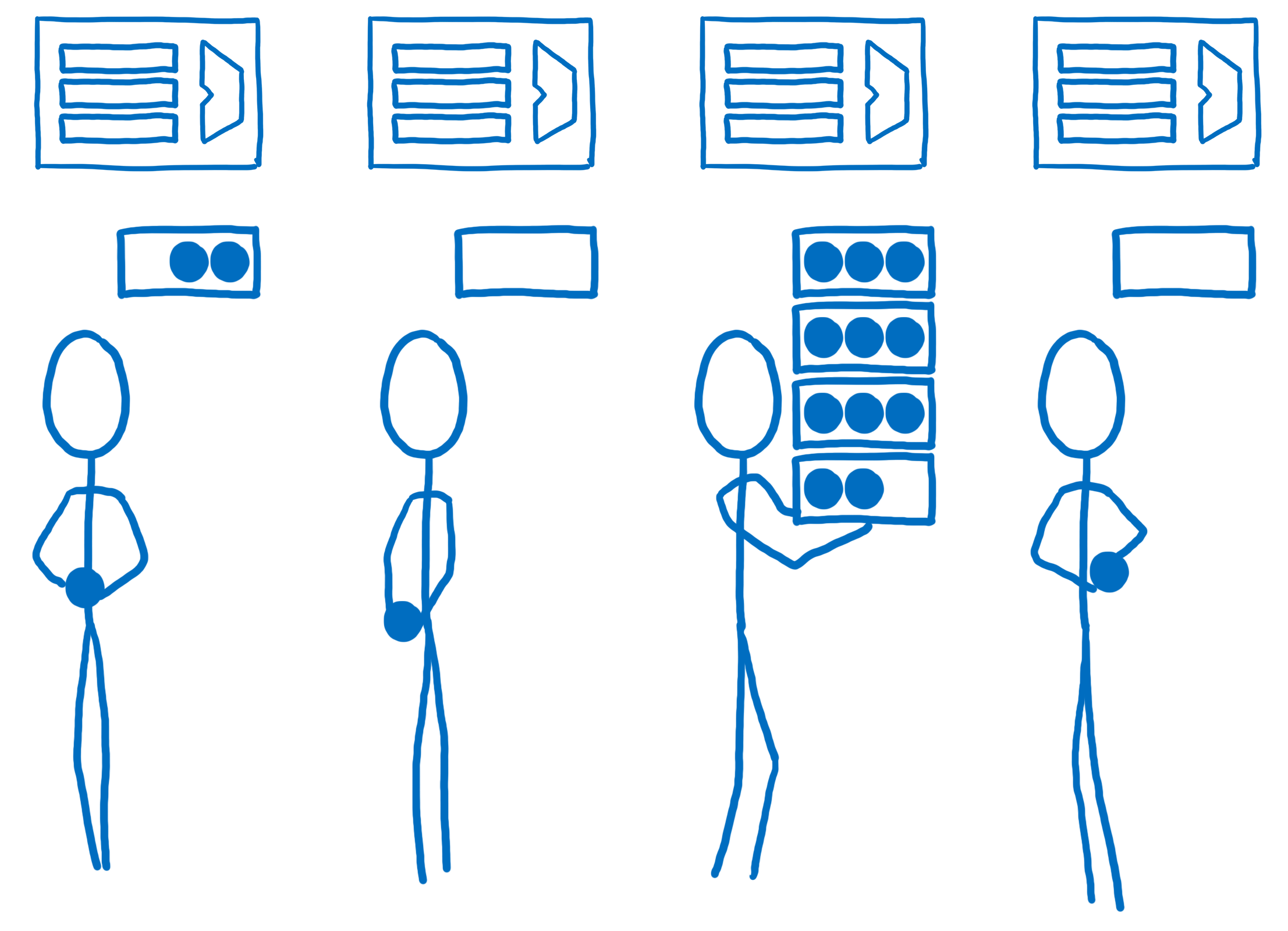
Cela paraît être facile à faire… simplement partager les branches de l’arbre DOM et les envoyer aux différents cœurs. C’est en réalité beaucoup plus difficile et ce pour plusieurs raisons. Une de ces raisons est que l’arbre DOM est souvent déséquilibré. Ainsi, un cœur aura beaucoup plus de travail que les autres.

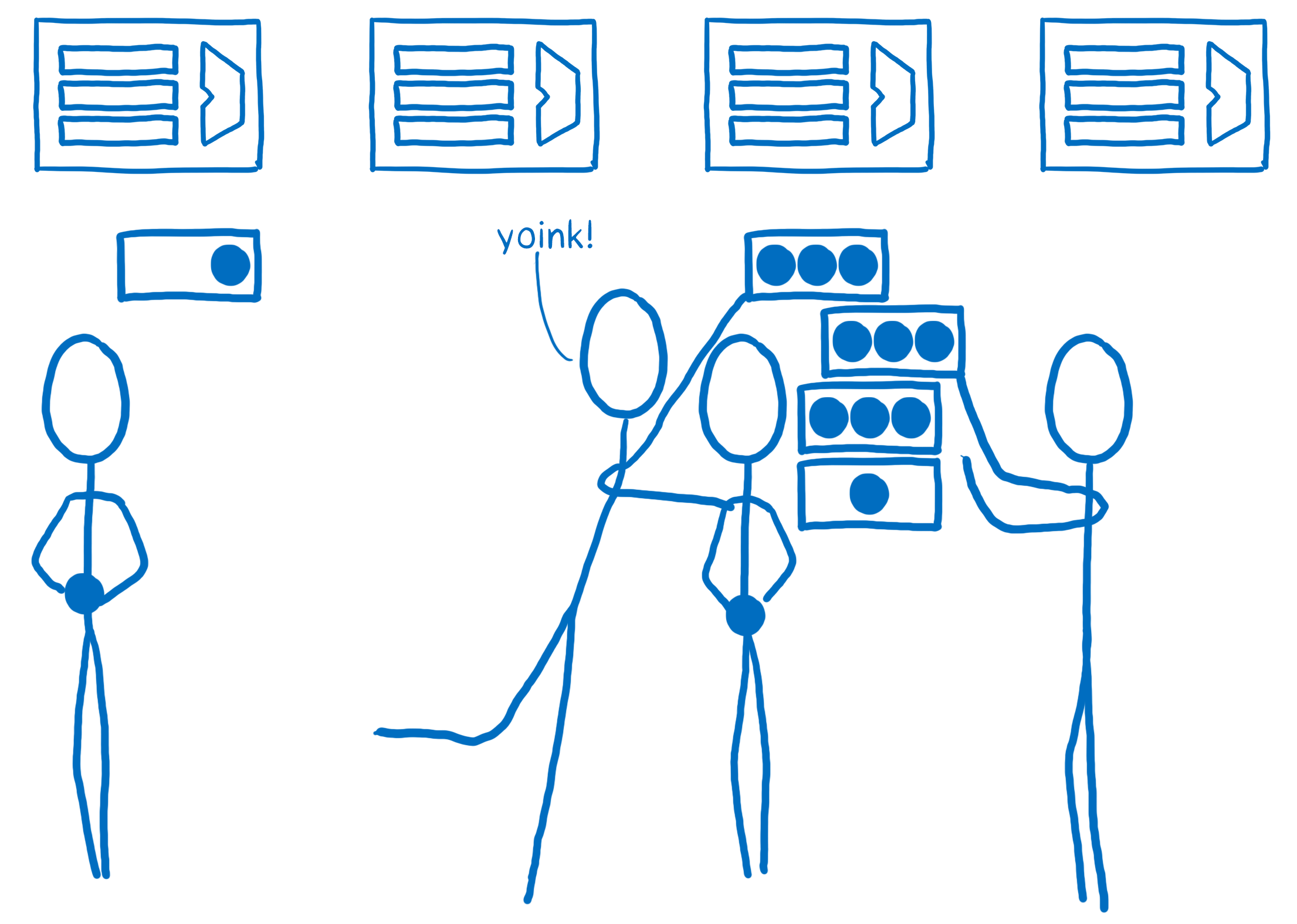
Pour répartir le travail plus équitablement, Quantum CSS utilise une technique nommée le vol de travail. Quand un nœud DOM est en train d’être analysé, le code reprend ses enfants directs et les partage en une ou plusieurs « unités de travail ». Ces unités de travail sont mises dans une queue.
Quand un cœur finit le travail de sa queue, il regarde la queue des autres pour trouver plus de travail à faire. Ainsi, nous pouvons séparer équitablement le travail sans perdre du temps pour traverser l’arbre et chercher comment l’équilibrer à l’avance.
Dans la plupart des navigateurs, il serait très difficile de le faire bien. Le parallélisme est un problème connu pour être difficile et le moteur CSS est très complexe. Il s’insère aussi entre les deux autres parties les plus complexes d’un moteur de rendu – le DOM et l’affichage. Ainsi, il est très facile de créer des bogues, et quand le parallélisme engendre des bogues, qui sont très difficiles à résoudre, ils sont appelés courses de données (data races). J’approfondis les explications sur ce type de problèmes dans un autre article.
Quand vous acceptez des contributions de centaines ou de milliers d’ingénieurs, comment pouvez-vous créer un programme parallélisé sans être effrayé ? C’est pour cela que nous avons Rust.

Avec Rust, vous pouvez vérifier statiquement que vous n’aurez pas de courses de données. C’est-à-dire que vous empêchez l’apparition de bogues difficiles à résoudre, simplement en vous empêchant de les créer dans votre code dès le début. Le compilateur ne vous laissera pas faire. Je suis en train d’écrire d’autres articles à ce sujet. Pour l’instant, vous pouvez voir cette vidéo d’introduction au sujet du parallélisme dans Rust ou celle-ci qui est une discussion plus détaillée sur le vol de travail.
Avec tout ceci, le calcul des styles CSS évolue de ce que nous appelions « un difficile problème de parallélisme » à « de très petits problèmes bloquant pour une exécution en parallèle efficace ». C’est-à-dire que nous pouvons nous rapprocher d’une accélération linéaire en termes de vitesse. Si vous avez 4 cœurs dans votre machine, alors cela pourra s’exécuter presque 4 fois plus vite.
Accélérer les recalculs de style avec l’arbre des règles
Pour chaque nœud DOM, le moteur CSS doit traverser toutes les règles pour faire la correspondance des sélecteurs CSS. Pour la plupart des nœuds, les correspondances ne changeront pas souvent. Par exemple, si l’utilisateur passe la souris sur un parent, les règles qui y sont liées pourraient changer. Nous devons donc encore recalculer les styles pour ses descendants pour appliquer correctement les propriétés héritées, mais les règles correspondant à ses descendants ne changeront probablement pas.
Ce serait mieux si nous pouvions simplement noter quelles règles correspondent à chaque descendant et ne pas avoir besoin de refaire le calcul des correspondances pour eux de nouveau… c’est ce que l’arbre des règles – emprunté du précédent moteur CSS de Firefox – fait.
Le moteur CSS effectue la recherche des sélecteurs qui correspondent et ensuite les trie par spécificité. De ceci, il crée une liste chaînée de règles.
Cette liste sera ajoutée à l’arbre des règles.
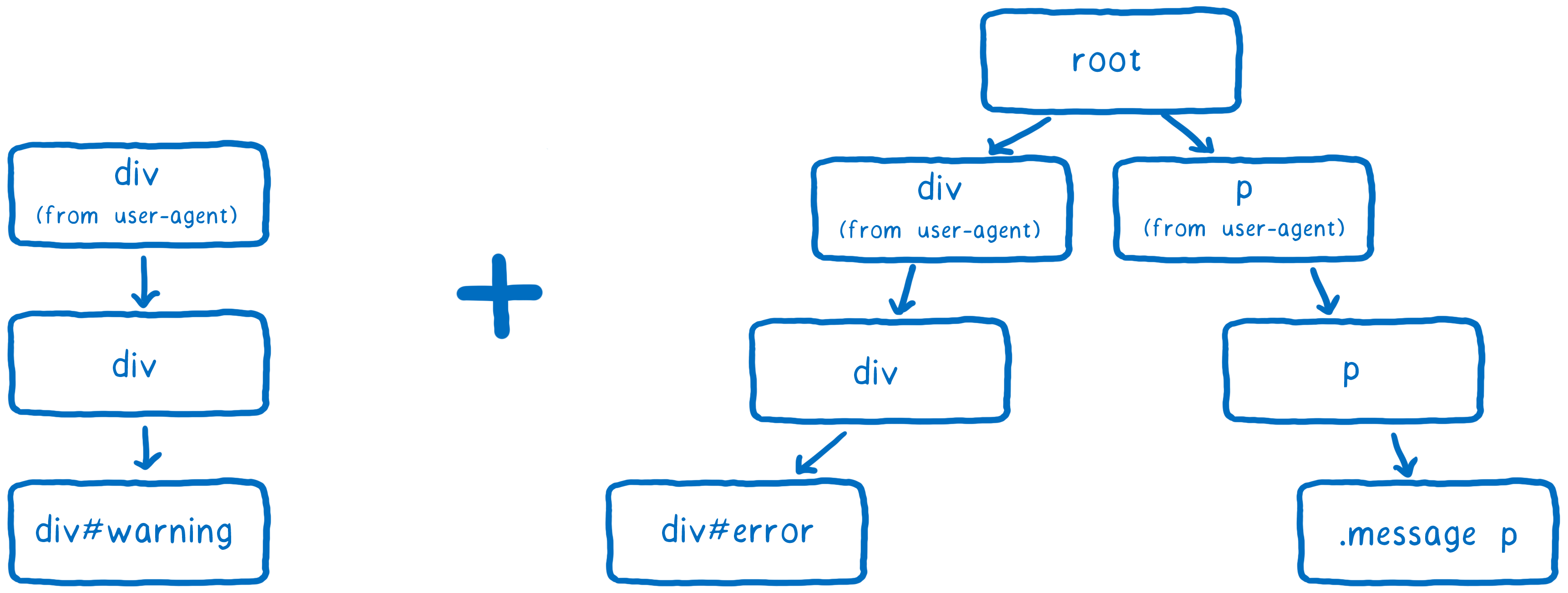
Le moteur CSS essaie de conserver le plus petit nombre de branches dans l’arbre. Pour cela, il essaie de réutiliser une branche dès qu’il peut.
Si la plupart des sélecteurs dans une liste sont les mêmes que dans une branche existante, alors il suivra le même chemin. Mais il pourrait atteindre un point où la règle suivante dans la liste n’est pas dans cette branche de l’arbre. Seulement à ce point il ajoute une nouvelle branche.
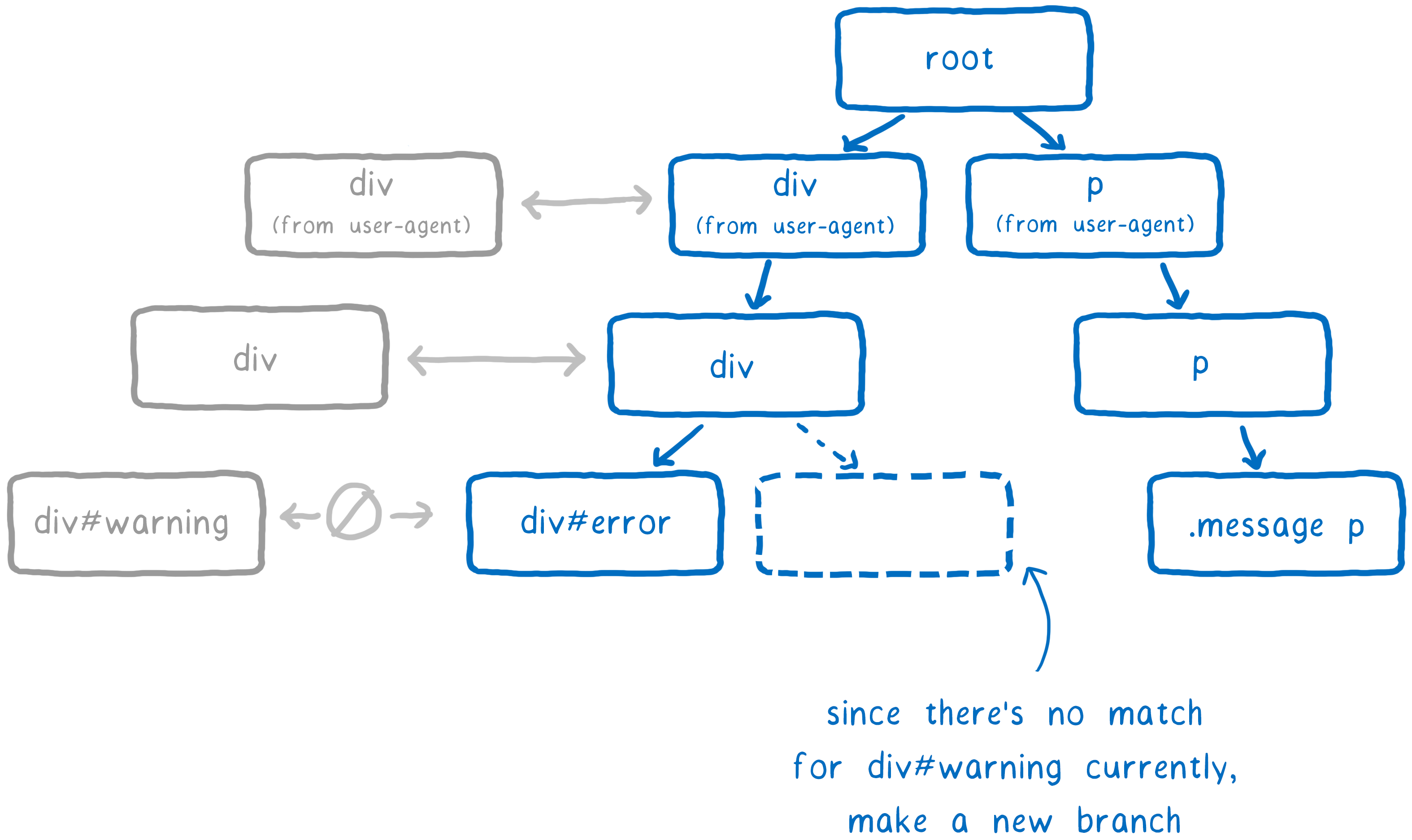
Le nœud DOM recevra un pointeur vers la règle qui a été insérée en dernier (dans cet exemple, la règle div#warning). C’est la plus spécifique.
Lors d’un recalcul de styles, le moteur fera une vérification rapide pour voir si le changement du parent modifie les règles qui correspondent aux enfants. Si les correspondances ne changent pas, alors pour tous les descendants, le moteur peut juste suivre le pointeur du nœud descendant pour obtenir la règle. De là, il peut remonter l’arbre jusqu’à la racine pour obtenir une liste complète de règles correspondantes, de la plus spécifique à la moins spécifique. Cela signifie qu’il peut complètement outrepasser les étapes de recherche de correspondance de sélecteurs et de leur tri.
Ainsi, cela aide à réduire le travail nécessaire durant le recalcul de styles. Mais il y a encore beaucoup de travail pour le premier calcul de styles. Si vous avez 10 000 nœuds, vous devez toujours faire la recherche de correspondance des sélecteurs 10 000 fois. Mais il y a un autre moyen d’accélérer tout ceci.
Accélérer le rendu initial (et la cascade) avec le cache partagé des styles
Pensez à une page avec des milliers de nœuds. Beaucoup de ces nœuds correspondront aux mêmes règles. Par exemple, pensez à un long article Wikipédia… les paragraphes dans le contenu principal devraient tous suivre exactement les mêmes règles et avoir donc les mêmes styles calculés.
S’il n’y avait pas d’optimisation, alors le moteur CSS devrait faire la correspondance des sélecteurs et calculer les styles pour chaque paragraphe individuellement. Mais s’il y avait un moyen pour prouver que les styles seront les mêmes d’un paragraphe à l’autre, alors le moteur ne devrait faire ce travail qu’une fois et il ferait pointer chaque nœud de paragraphe au même style calculé.
C’est ce que le cache partagé des styles – inspiré par Safari et Chrome – fait. Après avoir traité un nœud, il met le style calculé dans le cache. Ensuite, avant de débuter le calcul de styles du nœud suivant, il lance quelques vérifications pour voir s’il peut réutiliser les données du cache.
Ces vérifications sont :
- Est-ce que les deux nœuds ont les mêmes identifiants, classes, etc ? Si oui, alors ils vont correspondre aux mêmes règles.
- Pour ceux qui ne sont pas stylés depuis les sélecteurs – les styles inline par exemple –, est-ce que les nœuds ont les mêmes valeurs ? Dans ce cas, les règles au-dessus soit ne seront pas surchargées, soit elles seront surchargées, mais de la même manière.
- Est-ce que les deux parents pointent vers le même objet de styles calculés ? Si oui, alors les valeurs héritées seront identiques.

Ces vérifications ont été utilisées dès le début des premiers caches de styles partagés. Mais il y a beaucoup d’autres petits cas où les styles pourraient ne pas correspondre. Par exemple, si une règle CSS utilise le sélecteur :first-child, alors deux paragraphes ne pourraient pas correspondre, même quand les vérifications ci-dessus suggèrent que oui.
Dans WebKit et Blink, le cache partagé de styles est abandonné dans ces cas et le cache n’est pas utilisé. Comme de plus en plus de sites utilisent ces sélecteurs modernes, l’optimisation a été de moins en moins utile, à tel point que l’équipe Blink l’a récemment enlevée. Mais il s’avère qu’il y a un moyen d’utiliser le cache de styles partagés avec ces changements.
Dans Quantum CSS, nous rassemblons tous ces sélecteurs bizarres et vérifions s’ils s’appliquent au nœud DOM. Ensuite, nous stockons les réponses avec des uns et des zéros. Si les deux éléments ont le même nombre de uns et de zéros, nous savons qu’ils correspondent effectivement.

Si un nœud DOM peut partager des styles qui ont déjà été calculés, vous pouvez passer outre presque tout le travail. Comme les pages ont souvent beaucoup de nœuds DOM avec les mêmes styles, le cache de styles partagés peut économiser beaucoup de mémoire et vraiment accélérer les choses.

Conclusion
C’est le premier grand transfert de technologie de Servo vers Firefox. Durant ce chemin, nous avons beaucoup appris sur la manière d’apporter du code moderne et performant écrit en Rust dans le cœur de Firefox.
Nous sommes vraiment enthousiastes d’avoir rendu disponible cette grosse pièce du projet Quantum aux utilisateurs pour qu’ils l’expérimentent directement. Nous sommes très heureux de vous laisser l’essayer et, si vous rencontrez le moindre problème, faites-le-nous savoir.
-- Lin Clark
Adrien Dorsaz s’est lancé dans la traduction du billet de Lin Clark. La communauté de LinuxFr a relu le texte avant sa publication sur ce site. Avec son aimable assentiment, nous avons repris son texte qui a été relu par la communauté Mozilla francophone dont Mozinet, Goofy et Théo.
Cette traduction comme l’article original et la traduction de LinuxFr sur laquelle elle est basée sont sous licence CC By-SA 3.0 ou supérieure.
Précédent article sur le futur de Firefox : Mozilla Roadshow : ce qui arrive
Crédit illustrations : Lin Clark.
1 De bruno -
Bonjour, Vraiment intéressant ! et merci pour le traduction.