Tout le Web en FPS maximum : comment WebRender rend l’affichage plus fluide
Firefox Quantum est sorti le 14 novembre*. Cette version amènera des améliorations de performances, y compris le moteur CSS ultra rapide que nous avons importé de Servo.
Mais il reste une partie importante de la technologie de Servo qui n’est pas encore intégrée à Firefox Quantum, même si c’est pour bientôt. Il s’agit de WebRender, qui a été ajouté à Firefox dans le cadre du projet Quantum Render.
WebRender est connu pour être extrêmement rapide. En fait, WebRender n’est pas vraiment destiné à faire du rendu plus rapide. Il cherche à le rendre plus fluide.
Avec l’utilisation de WebRender, nous voulons des applications qui tournent de manière fluide, à au moins 60 images par seconde (FPS), quelle que soit la taille de la fenêtre d’affichage ou le nombre de modifications sur chaque image. Et cela fonctionne. Des pages qui rament à 15 FPS dans Chrome ou dans la version actuelle de Firefox sont affichées à 60 FPS avec WebRender.
Comment fait WebRender ? Fondamentalement, il change la façon dont fonctionne le moteur de rendu pour le faire ressembler à un moteur de jeux 3D.
Voyons voir ce que cela signifie. Mais d’abord…
Que fait un moteur de rendu ?
Dans l’article sur Stylo, j’ai expliqué comment le navigateur transforme le code HTML et CSS en pixels affichés sur un écran et comment la plupart des navigateurs réalisent cela en cinq étapes.
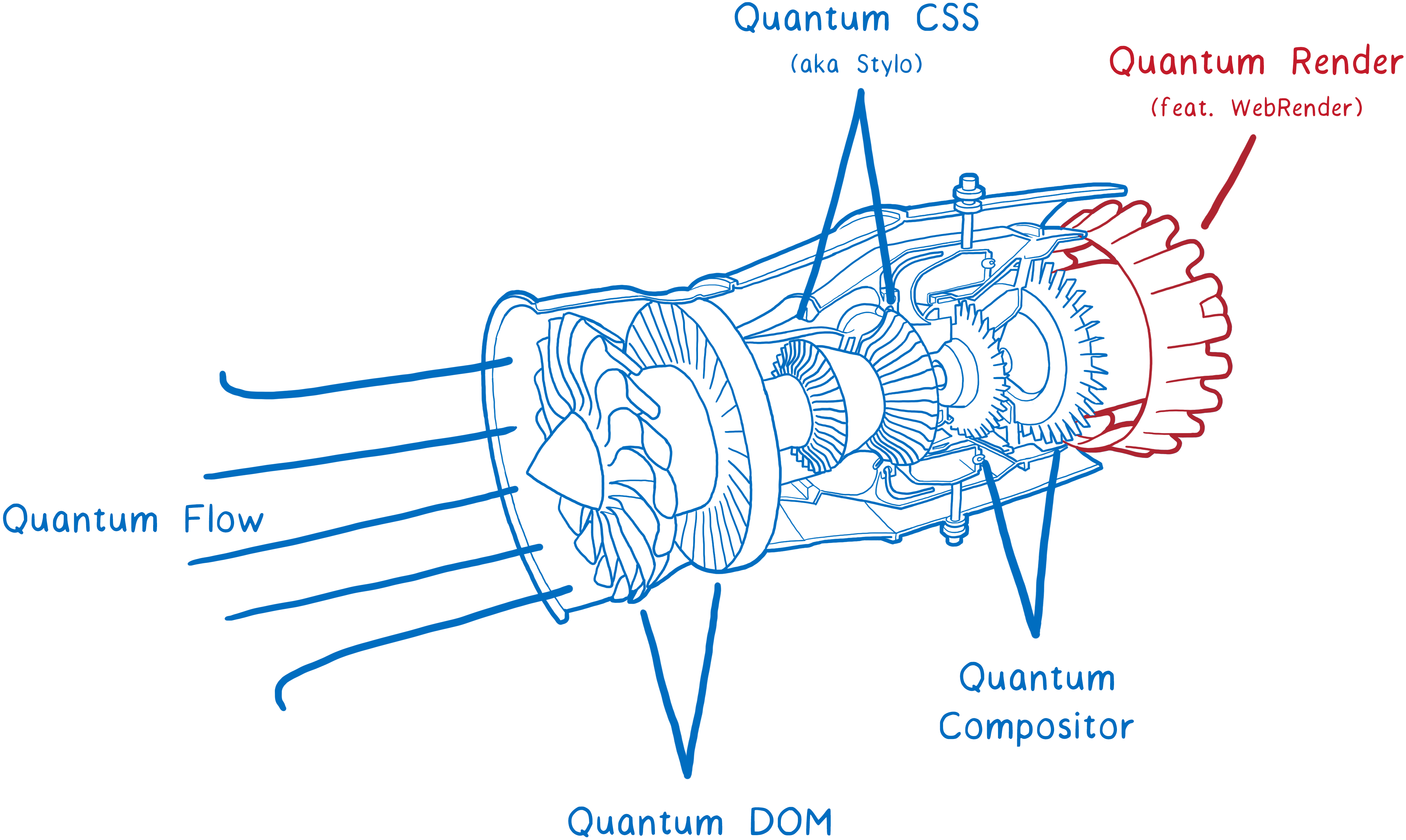
On peut séparer ces cinq étapes en deux parties. En simplifiant, la première partie construit un plan. Pour cela le navigateur combine le code HTML et CSS avec des informations sur la taille de l’écran pour décider exactement à quoi chaque élément doit ressembler (hauteur, largeur, couleur…). Le résultat est appelé l’arbre d’images (frame tree) ou arbre de rendu (render tree).
La seconde partie, le dessin et la composition, est ce qui est pris en charge par le moteur de rendu. Il transforme le plan en pixels à afficher sur l’écran.
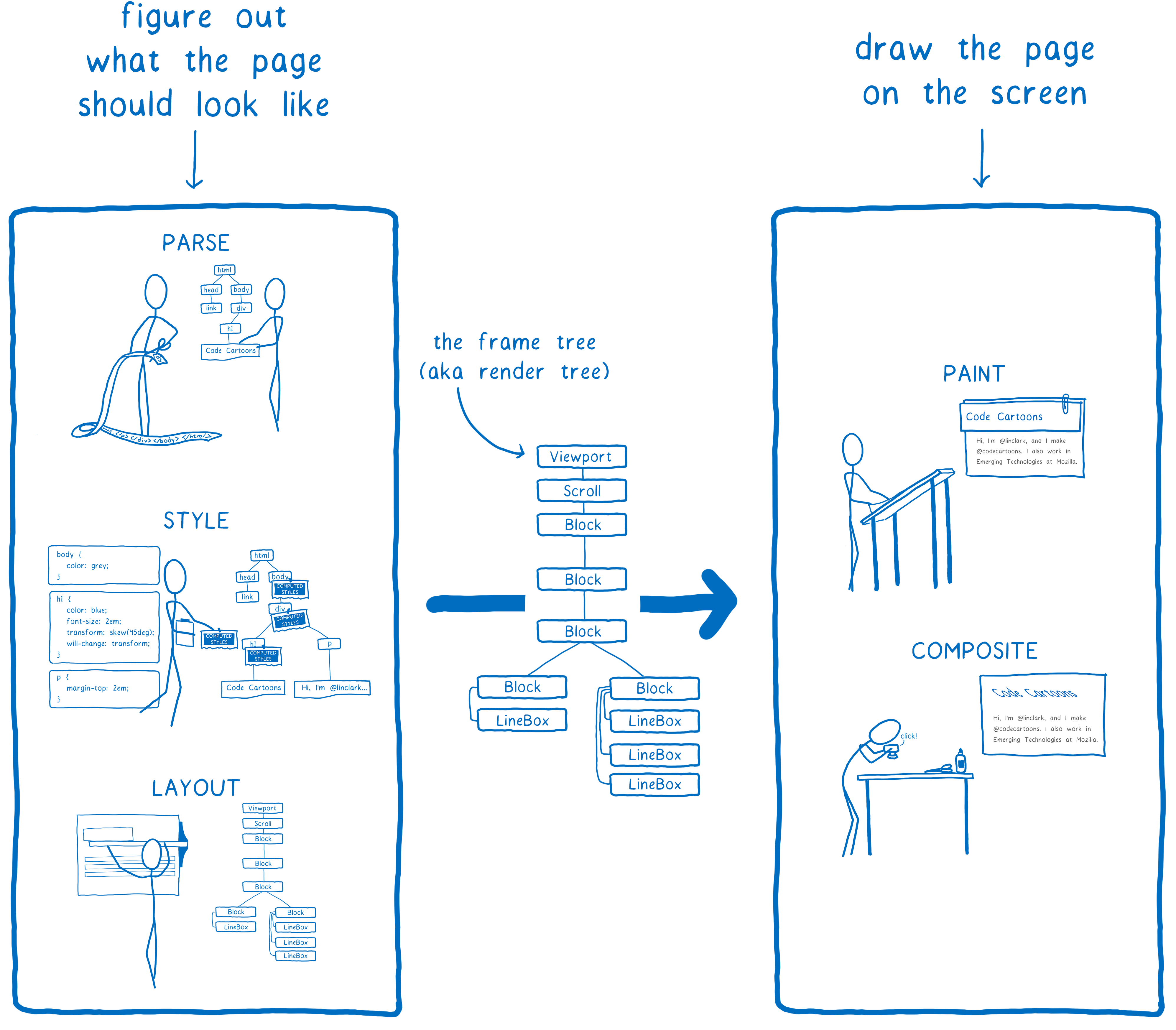
Mais le navigateur ne doit pas le faire qu’une seule fois par page. Il doit le faire encore et encore pour la même page. À chaque fois que quelque chose change sur cette page, par exemple une div est ouverte, le navigateur doit refaire ces cinq étapes.
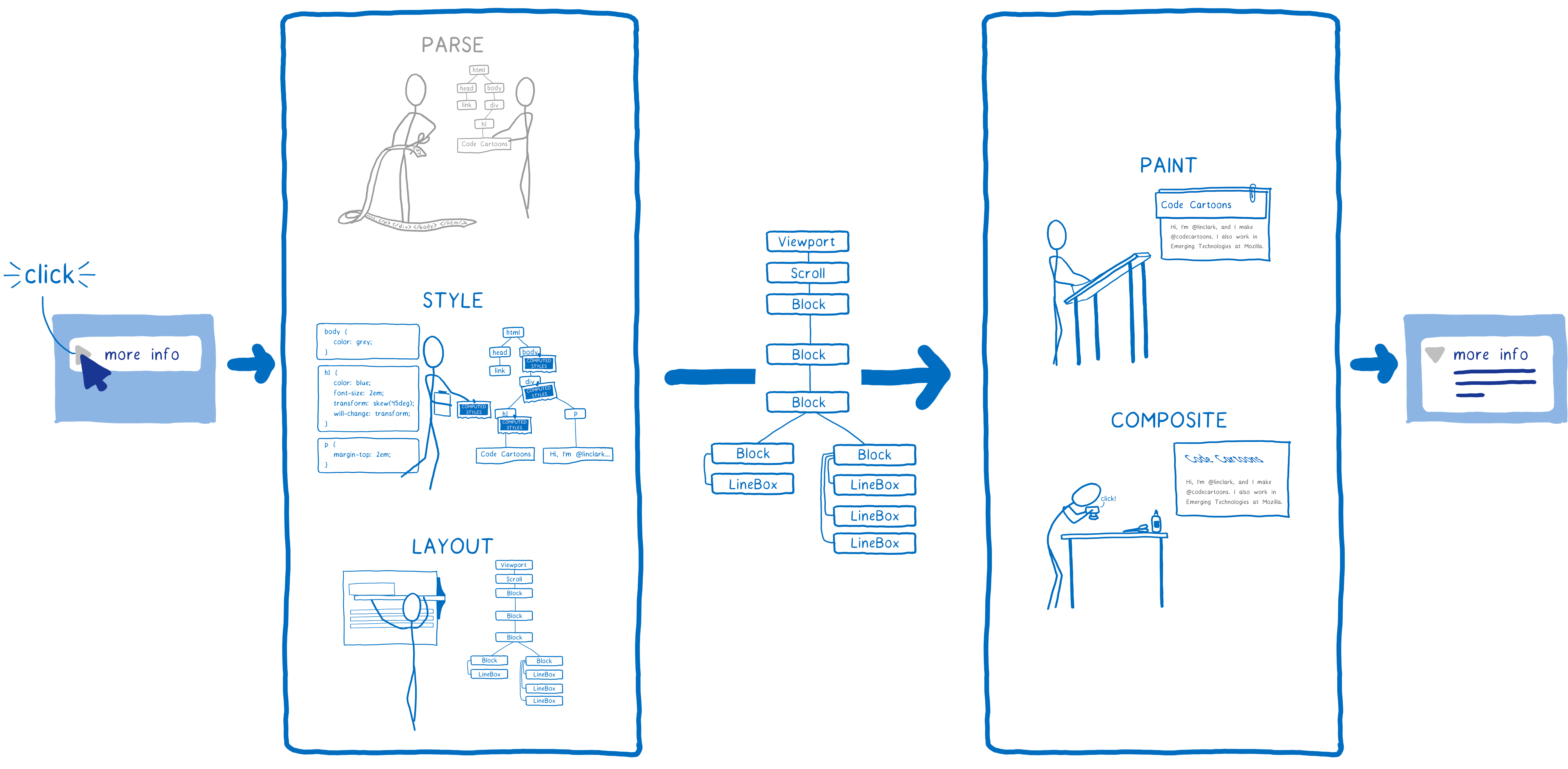
Même dans les cas où rien ne change vraiment sur une page, par exemple lorsque vous la faites défiler ou que vous mettez en surbrillance une partie du texte, le navigateur refait au moins les étapes de la seconde partie pour modifier les pixels sur l’écran.

Si vous voulez que le défilement ou les animations soient fluides, ces opérations doivent être effectuées à une vitesse de 60 FPS.
Vous avez peut-être déjà entendu ces mots « frames per second » ou FPS sans savoir vraiment ce qu’ils veulent dire. J’aime comparer ce concept à un folioscope. Il s’agit d’un de ces livres contenant des dessins qui sont statiques, mais en utilisant son pouce, on peut faire défiler les feuilles pour voir les dessins s’animer.
Pour que l’animation du folioscope paraisse fluide, il faut faire défiler 60 pages par seconde.
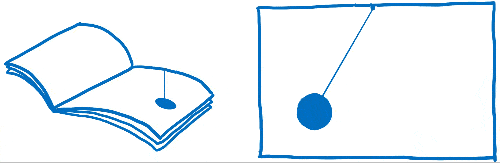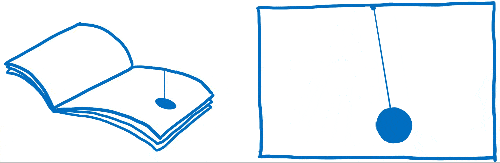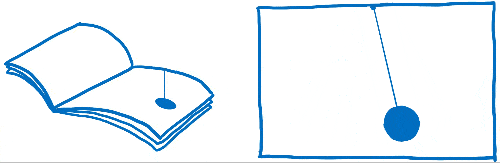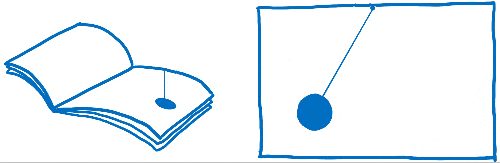
Les pages de ce livre sont en papier millimétré. Il y a énormément de petits carrés, et chacun d’entre eux ne peut contenir qu’une seule couleur.
Le travail du moteur de rendu est de remplir les carrés de ce papier millimétré. Quand tous les carrés sont coloriés, il a terminé le rendu de l’écran.
Bien entendu, il n’y a pas de papier millimétré dans votre ordinateur. On trouve plutôt une partie de la mémoire de l’ordinateur appelée tampon graphique. Chaque adresse de mémoire dans le tampon graphique est comme un carré du papier millimétré et elle correspond à un pixel à l’écran. Le navigateur remplit chaque adresse de mémoire avec les nombres qui correspondent à la couleur avec des valeurs RGBA (rouge, vert, bleu et transparence).

À chaque fois que l’écran a besoin de se rafraîchir, il va chercher l’information dans cette partie de la mémoire.
La plupart des moniteurs rafraîchissent 60 fois par seconde. C’est pour cela que les navigateurs essaient de faire le rendu des pages à 60 FPS. Ce qui veut dire que le navigateur dispose de 16,67 millisecondes pour faire toutes les étapes (style CSS, disposition et dessin) et remplir tous les éléments dans le tampon graphique avec des pixels de couleur. Cette durée entre deux images est appelée l’enveloppe budgétaire d’image (frame budget).
Parfois, on entend parler d’images sautées. On emploie ce terme quand le système n’a pas terminé son travail à l’issue de l’enveloppe budgétaire d’image (frame budget). L’affichage essaie de récupérer la nouvelle image depuis le tampon graphique avant que le navigateur ait fini de la remplir. Dans ce cas, l’affichage remontre la version précédente de l’image.
Dans un folioscope, une image sautée correspondrait à une page arrachée. L’animation donnerait l’impression de bégayer ou de faire un bond, car il manquerait une transition entre deux pages.
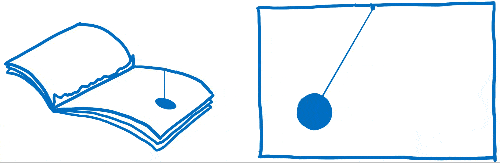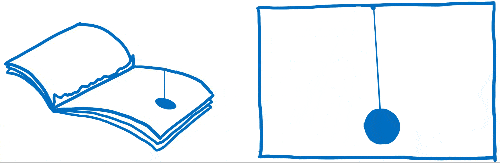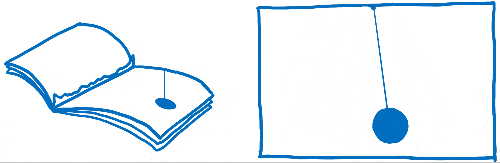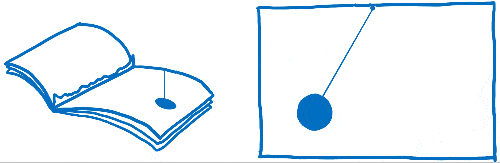
Nous voulons donc nous assurer d’avoir tous les pixels dans le tampon graphique avant que l’affichage ne vienne le chercher. Regardons comment les navigateurs ont réalisé ces étapes jusqu’ici et quelles ont été les évolutions. Ensuite, nous pourrons voir comment nous pouvons accélérer ces étapes.
Un bref historique du dessin et de la composition
Note : réaliser le dessin et la composition sont les opérations qui différencient le plus les navigateurs. Les navigateurs qui ne sont que sur un type de plateforme (Edge et Safari) fonctionnent de manière différente des navigateurs multiplateformes (Firefox et Chrome).
Même dans les premières versions des navigateurs, il existait des optimisations pour fluidifier le rendu. Par exemple, si vous faisiez défiler du contenu vers le bas, le navigateur gardait la partie visible et la déplaçait pour, dans un deuxième temps, dessiner les pixels dans l’espace vide.
Le processus visant à déterminer ce qui a changé et ne mettre à jour que ces éléments-là s’appelle l’invalidation.
Au fur et à mesure, les navigateurs ont développé l’utilisation des techniques d’invalidation comme l’invalidation en rectangle. Grâce à cette méthode, on détermine les plus petits rectangles contenant un élément qui a changé à l’écran. Ensuite, on ne redessine que ce qui se situe dans ces rectangles.
Cela réduit considérablement le travail, surtout quand il n’y a pas grand-chose à changer sur une page… par exemple lorsqu’il y a un curseur clignotant.
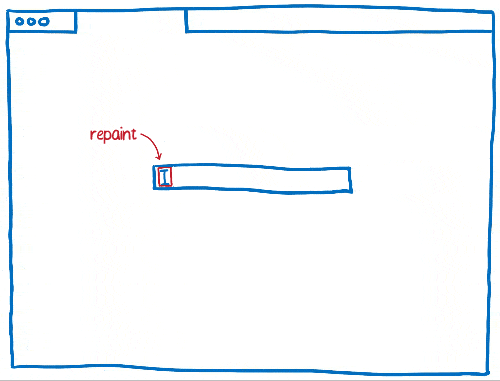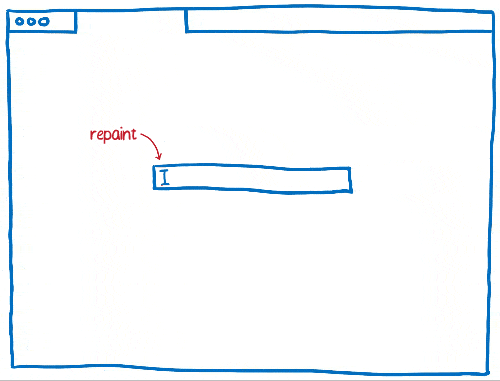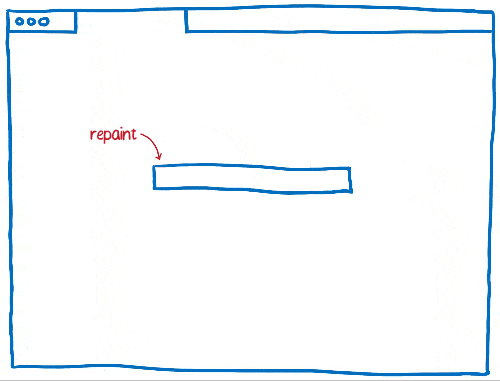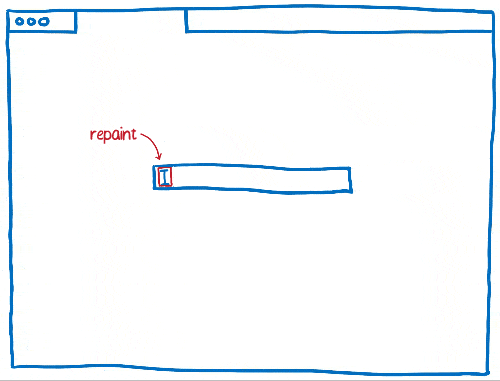
En revanche, cela ne nous aide pas beaucoup lorsqu’une grande partie de la page évolue. Les navigateurs ont donc progressé pour gérer ce genre de situation.
Introduction aux calques et à la composition
Utiliser des calques peut s’avérer utile lorsqu’une grande partie de la page change… au moins dans certains cas.
Les calques dans les navigateurs sont semblables aux calques dans Photoshop ou à ceux utilisés dans les premiers dessins animés. Il s’agit de dessiner différents éléments sur différents calques pour ensuite les superposer.
Ils existent depuis longtemps dans les navigateurs, mais n’ont pas toujours été utilisés pour accélérer le rendu. Au début, ils n’étaient là que pour s’assurer que les pages étaient affichées correctement. Ils correspondaient alors à de l’empilement de contextes.
Par exemple, si vous disposiez d’un élément translucide, ce dernier possédait son propre contexte. De cette manière, il pouvait laisser passer la couleur de l’élément en arrière-plan. Ces calques étaient supprimés dès le rendu de l’image. Sur l’image suivante, les calques devaient être dessinés à nouveau.
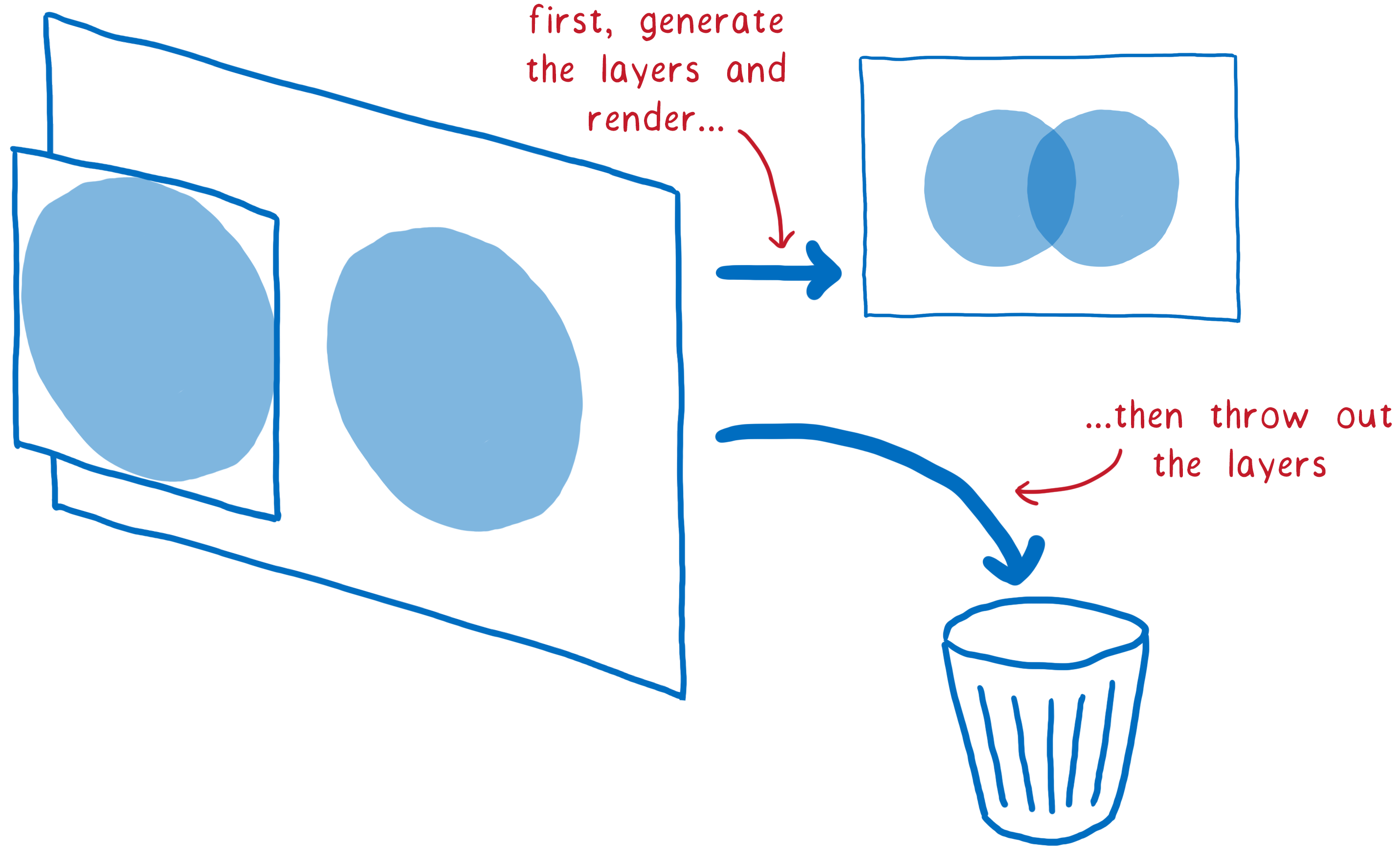
Bien souvent, les éléments de ces calques ne changeaient pas d’une image à l’autre. Vous pouvez imaginer une animation traditionnelle. Dans ce cas, le fond ne change pas, même si les personnages au premier plan évoluent. Il est donc beaucoup plus efficace de conserver le calque du fond et de le réutiliser ensuite.
C’est ce que les navigateurs ont fait. Ils ont conservé les calques. Ainsi, le navigateur n’avait qu’à redessiner les calques qui avaient évolué. Et dans certains cas, les calques ne changeaient même pas. Il fallait simplement les réorganiser, comme lorsqu’une animation se déplace sur l’écran ou que l’utilisateur fait défiler un élément.
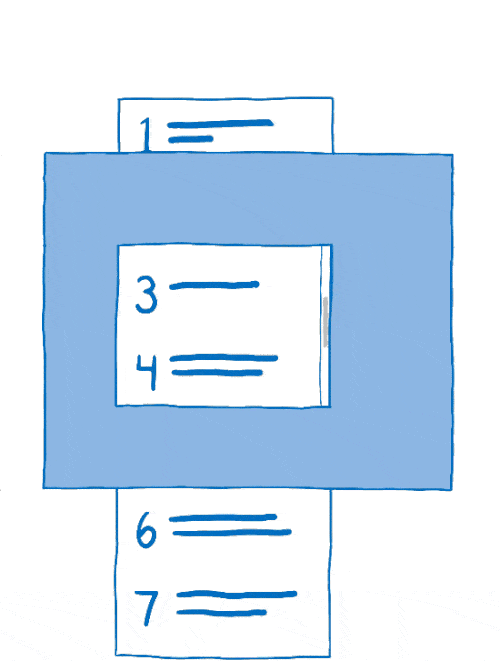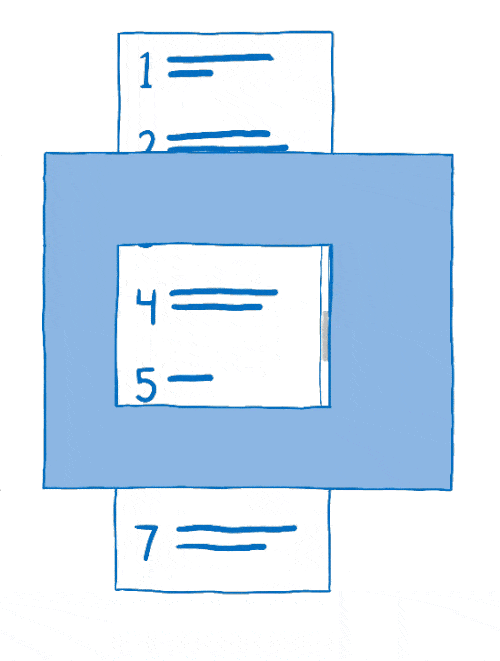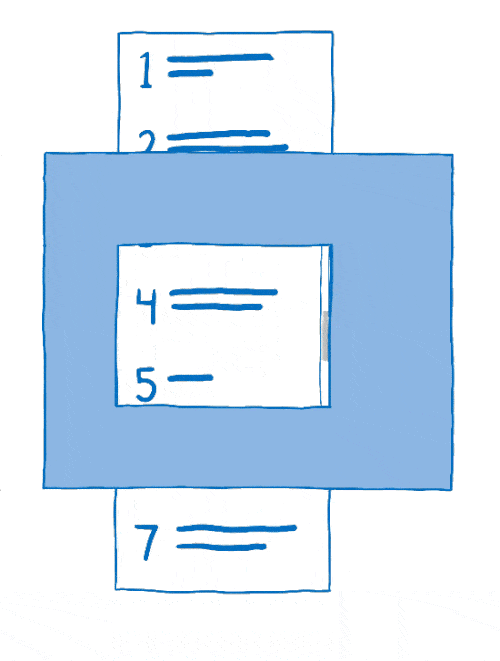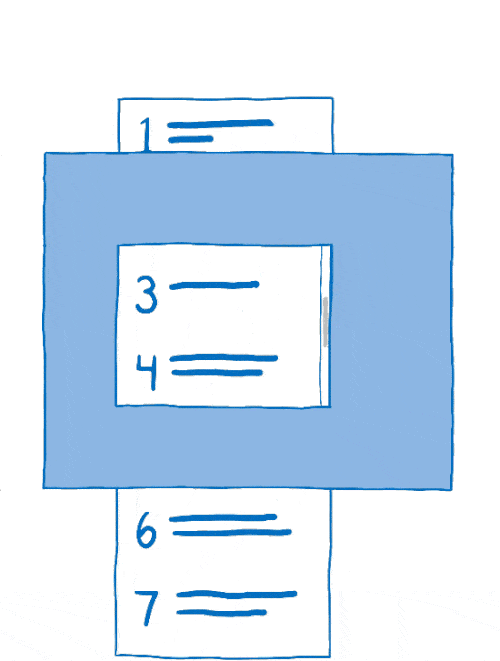
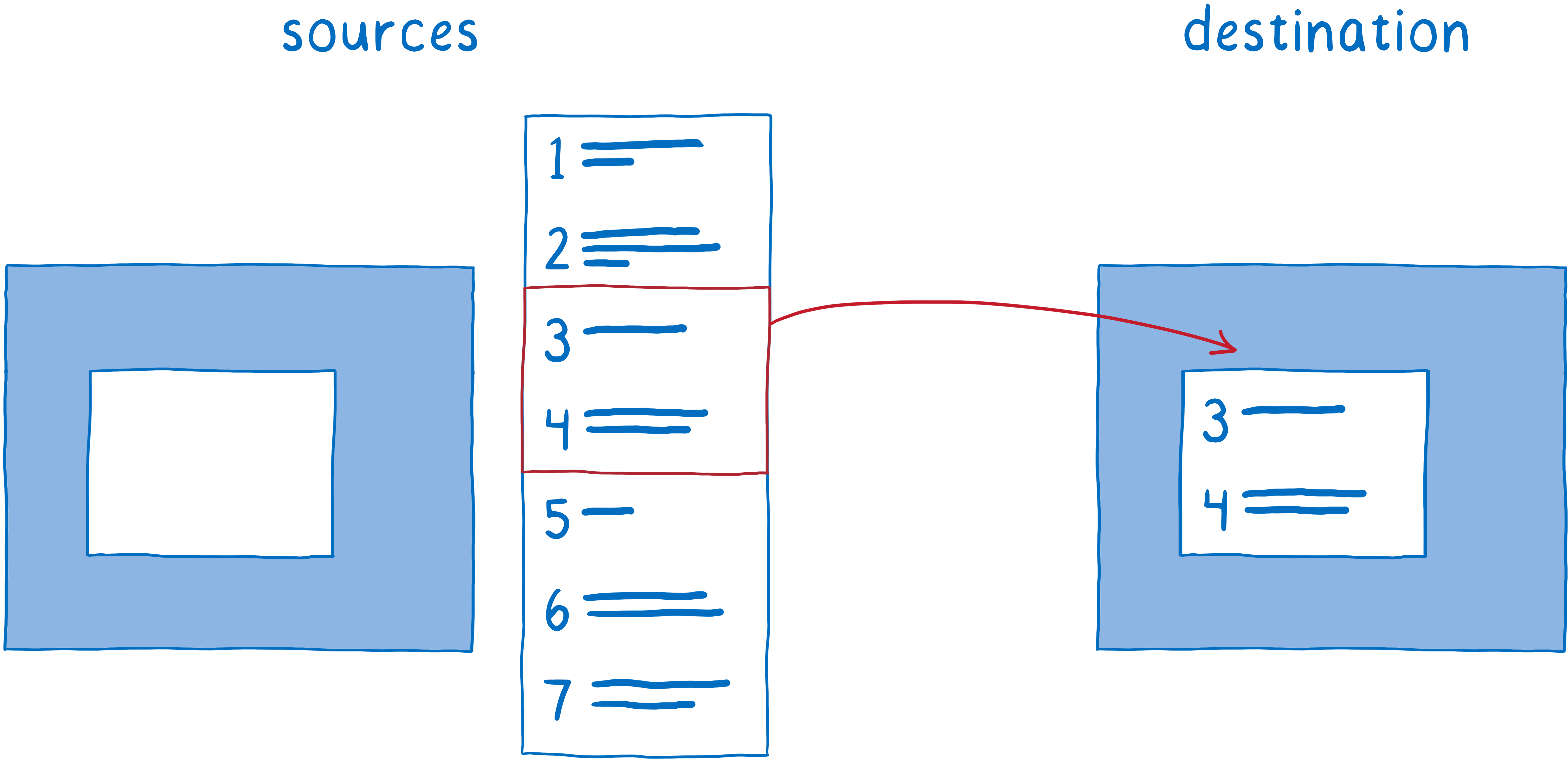
Le processus qui consiste à arranger les calques entre eux est appelé la composition. Le compositeur commence avec :
- des images sources : le fond (incluant un cadre blanc où le contenu pouvant défiler doit se situer) ainsi que le contenu mobile ;
- l’image de destination, ce qui doit être affiché à l’écran.
Le compositeur commençait en copiant l’arrière-plan sur l’image de destination.
Ensuite, il déterminait la partie du contenu mobile à afficher. Il copiait alors cette partie sur l’image de destination.
Cela réduisait la charge de travail du processus principal pour effectuer le dessin. Néanmoins, le processus principal dédiait beaucoup de temps à la composition. Il ne faut pas oublier qu’en même temps d’autres tâches doivent aussi être gérées par le processus principal.
J’ai déjà abordé le sujet, mais le processus principal est un peu comme un développeur qui s’occupe à la fois de l’interface, du serveur et de l’architecture. Ici le processus principal se charge du DOM, de la disposition de la page et du JavaScript, mais il doit aussi gérer le dessin et la composition.

Chaque milliseconde passée par le processus principal sur le dessin et la composition, c’est du temps en moins pour le JavaScript ou la disposition de la page.

En fait, il y a une partie matérielle qui n’avait pas beaucoup de travail à faire, quand bien même sa spécialité est de faire du rendu graphique. C’était le processeur graphique (GPU) que les jeux vidéos utilisent depuis la fin des années 90 pour afficher des images de façon rapide ; sans parler du fait que la puissance et la taille des cartes graphiques n’ont cessé d’augmenter.
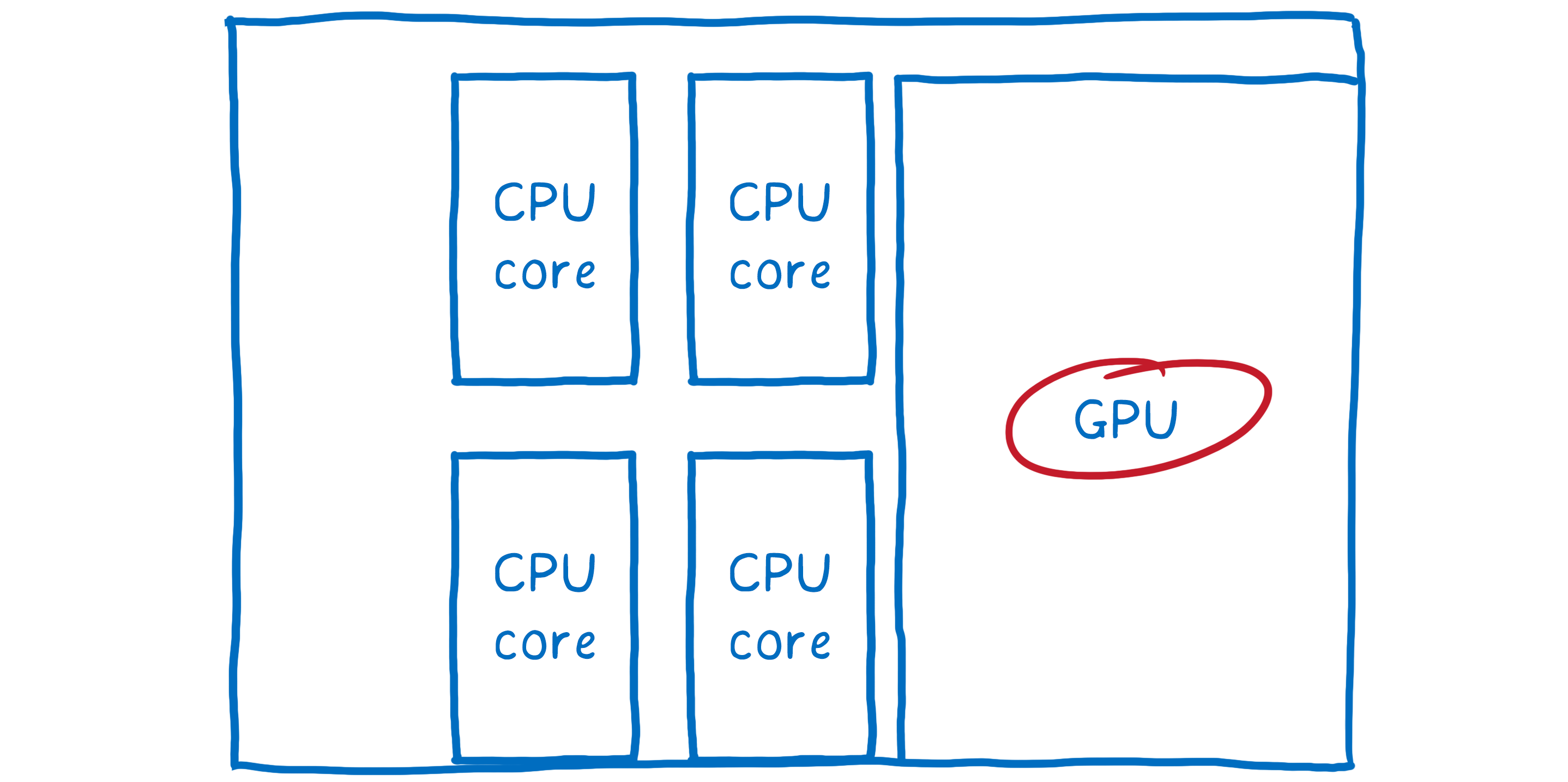
Composition accélérée par carte processeur
Du coup les développeurs ont transféré des tâches au processeur graphique.
Il y a deux tâches qui étaient potentiellement aptes à migrer vers le processeur graphique :
- effectuer le dessin des calques ;
- composer l’ensemble.
Le dessin en lui-même peut s’avérer complexe à transférer vers le processeur graphique. Pour la plupart, les navigateurs multiplateformes ont laissé le processeur principal s’occuper du dessin.
La composition en revanche pouvait être effectuée en un temps record par le processeur graphique, sans compter qu’il était facile de migrer cet aspect vers le processeur graphique.

Certains navigateurs sont allés encore plus loin en termes de parallélisation et ont créé un processus dédié au sein du processeur pour s’occuper de la composition. Ce processus est devenu un gestionnaire du travail de composition qui avait lieu dans graphique. Ainsi, lorsque le processus principal du navigateur était occupé à faire quelque chose comme exécuter du JavaScript, le compositeur pouvait toujours afficher du contenu à l’utilisateur, comme faire défiler la page vers le haut.
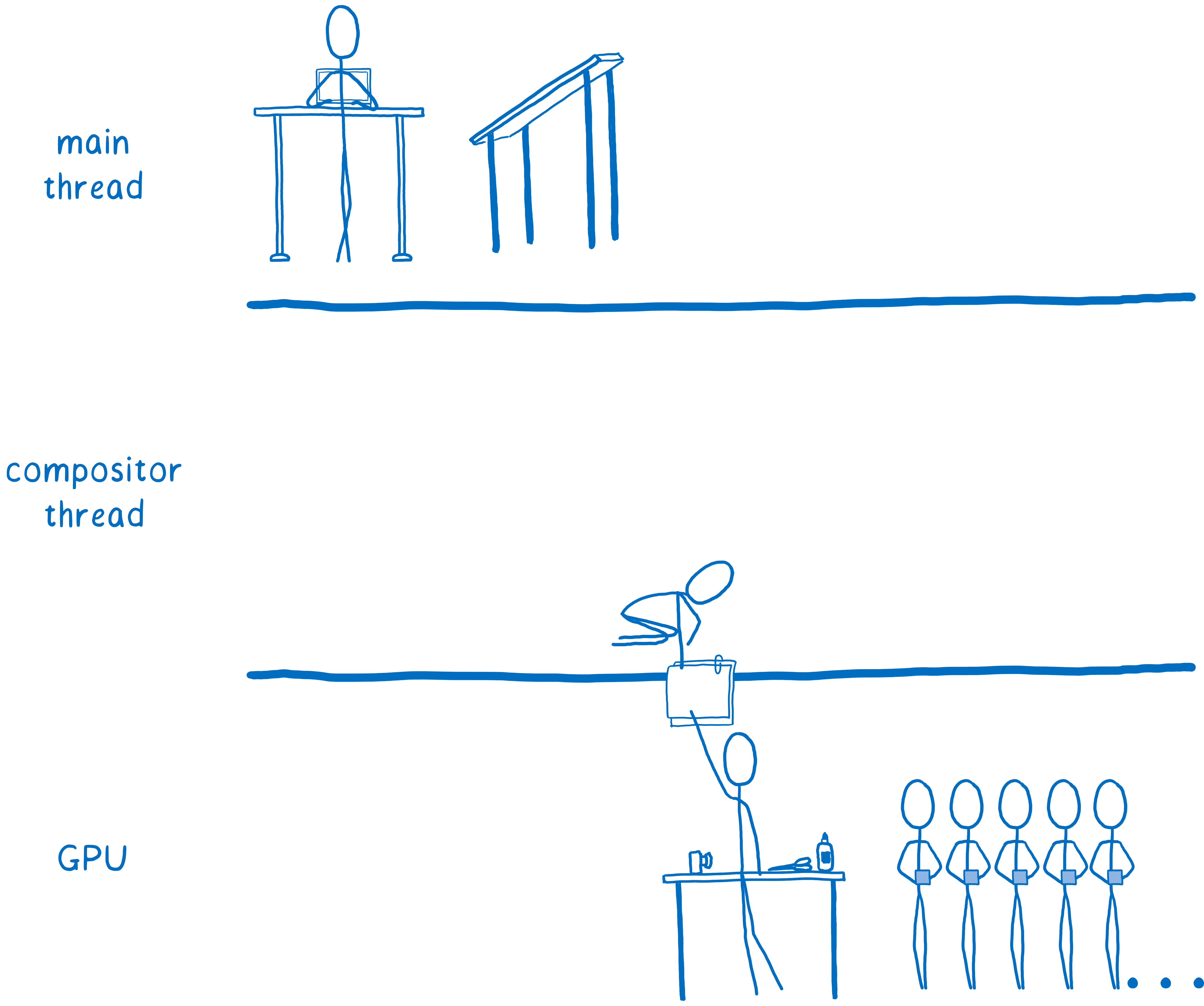
De cette manière, l’ensemble de la charge de travail est en dehors du processus principal. Mine de rien, il reste encore beaucoup de choses qui doivent être gérées par ce processus. Lorsqu’il s’agit de redessiner un calque, c’est au processus principal de s’en charger pour ensuite le transférer au processeur graphique.
Certains navigateurs ont migré le dessin sur un autre processus (on est en train de travailler dessus pour Firefox). En réalité, il est encore plus rapide de passer cette dernière partie (le dessin) au processeur graphique.
Dessin accéléré par processeur graphique
Ainsi, les navigateurs ont aussi commencé à transférer le dessin au processeur graphique.
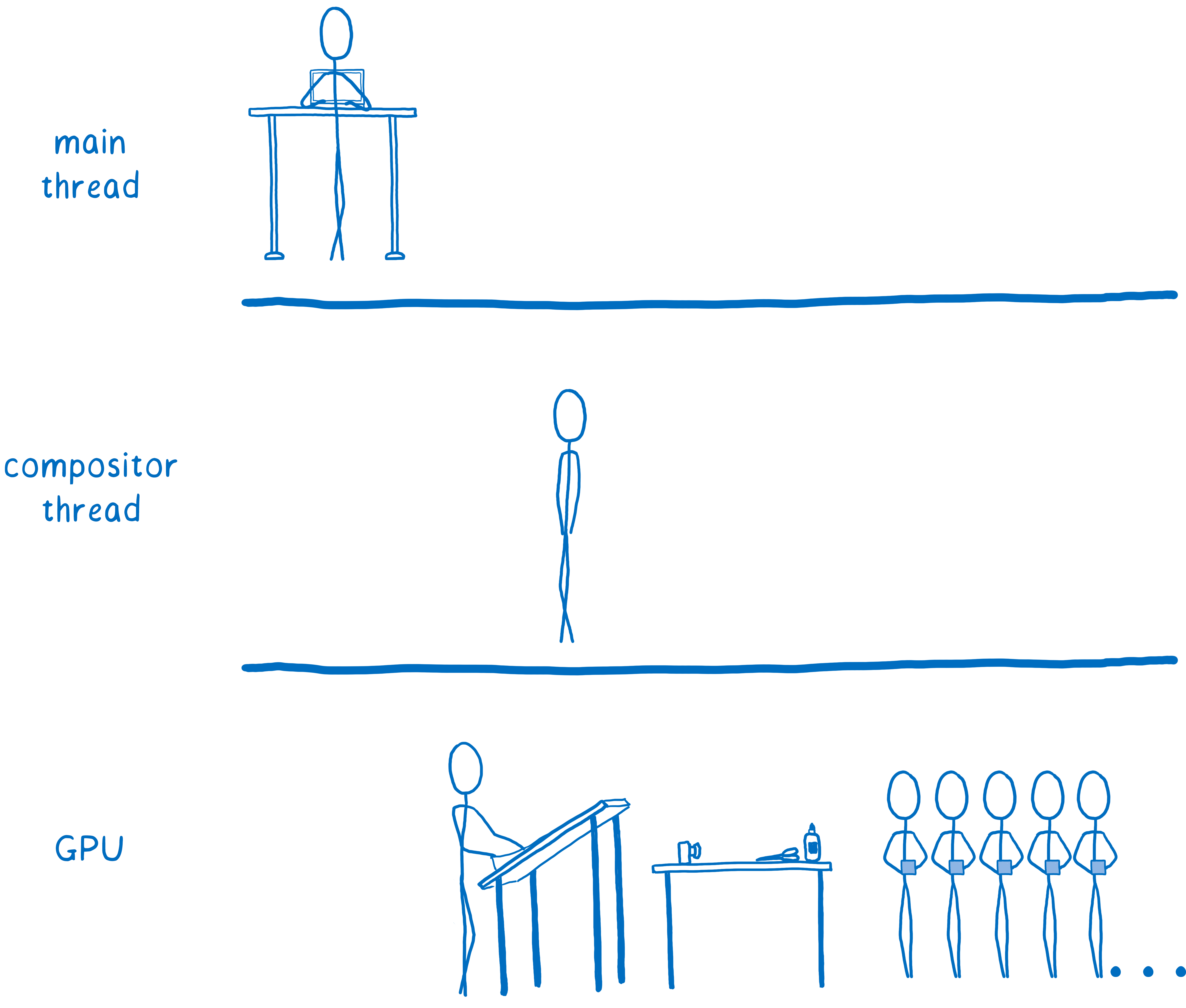
Les navigateurs n’ont pas totalement fini de passer de l’un à l’autre. Certains n’utilisent plus que le processeur graphique, tandis que d’autres le font sur certaines plateformes uniquement (sur Windows ou sur smartphones par exemple).
Faire faire le dessin par le processeur graphique permet certaines choses. D’une part, le processeur peut désormais consacrer son temps au JavaScript et à l’organisation de la page. D’autre part les processeurs graphiques sont beaucoup plus rapides pour créer un pixel que les processeurs principaux, on accélère de fait le dessin. Enfin, cela signifie que moins de données doivent être copiées du processeur vers le processeur graphique.
Cependant, avoir le dessin d’un côté et la composition de l’autre reste coûteux même lorsque les deux sont effectués par le processeur graphique. Cette séparation limite aussi les optimisations qui permettraient d’augmenter les performances du processeur graphique.
C’est là que WebRenderer rentre en jeu. Il modifie de manière fondamentale la manière dont le rendu global s’effectue en faisant disparaître la barrière entre dessin et composition. Nous pouvons alors optimiser notre moteur de rendu afin de délivrer la meilleure expérience utilisateur pour le Web d’aujourd’hui et faire face aux défis du Web de demain.
Cela ne signifie pas uniquement que nous voulons afficher les images plus rapidement… nous voulons aussi les afficher de manière homogène et sans saccade. Même lorsqu’il y a beaucoup de pixels à gérer comme sur un écran 4K ou sur un casque de réalité virtuelle via WebVR, nous voulons que l’expérience demeure tout aussi agréable.
Qu’est-ce qui fait que les navigateurs peuvent avoir des ratés à l’affichage ?
Les optimisations que nous avons mentionnées ont permis d’afficher les pages plus rapidement dans certains cas. Par exemple lorsqu’il n’y a qu’un curseur clignotant sur la page, il n’y a pas beaucoup de changements et le navigateur fera le moins de travail possible.
En décomposant la page en calques, le nombre de scénarios optimaux a augmenté. S’il s’agit uniquement de dessiner quelques calques et de les agencer, l’architecture dessin + composition fonctionne.
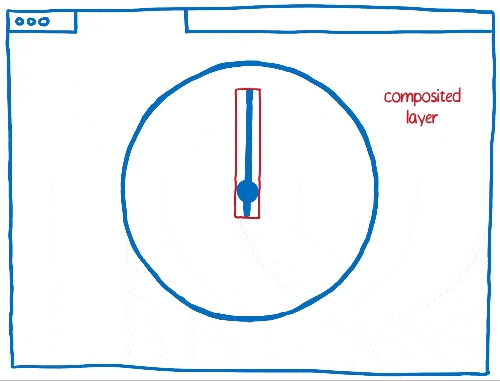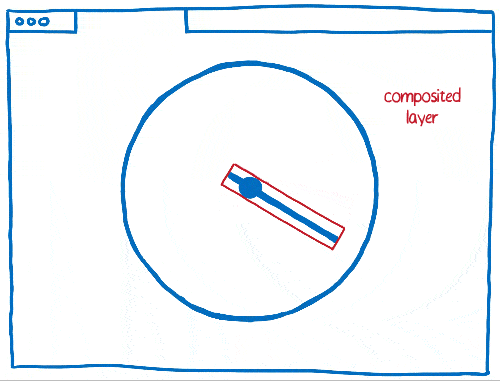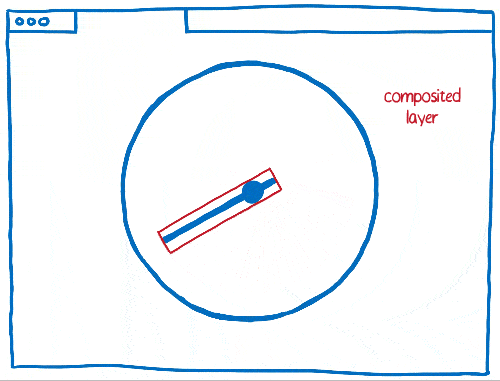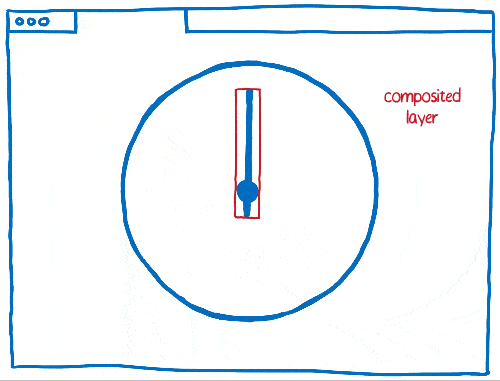
Travailler avec les calques implique aussi certains compromis. Ils sont gourmands en mémoire et peuvent aussi ralentir l’ensemble. Les navigateurs doivent pouvoir combiner les calques lorsque c’est pertinent, mais il est assez compliqué de savoir si c’est effectivement le cas.
En ayant beaucoup d’éléments mobiles à gérer au sein d’une page, il peut arriver qu’il y ait trop de calques. Ces derniers remplissent la mémoire et prennent trop de temps pour être transférés au compositeur.
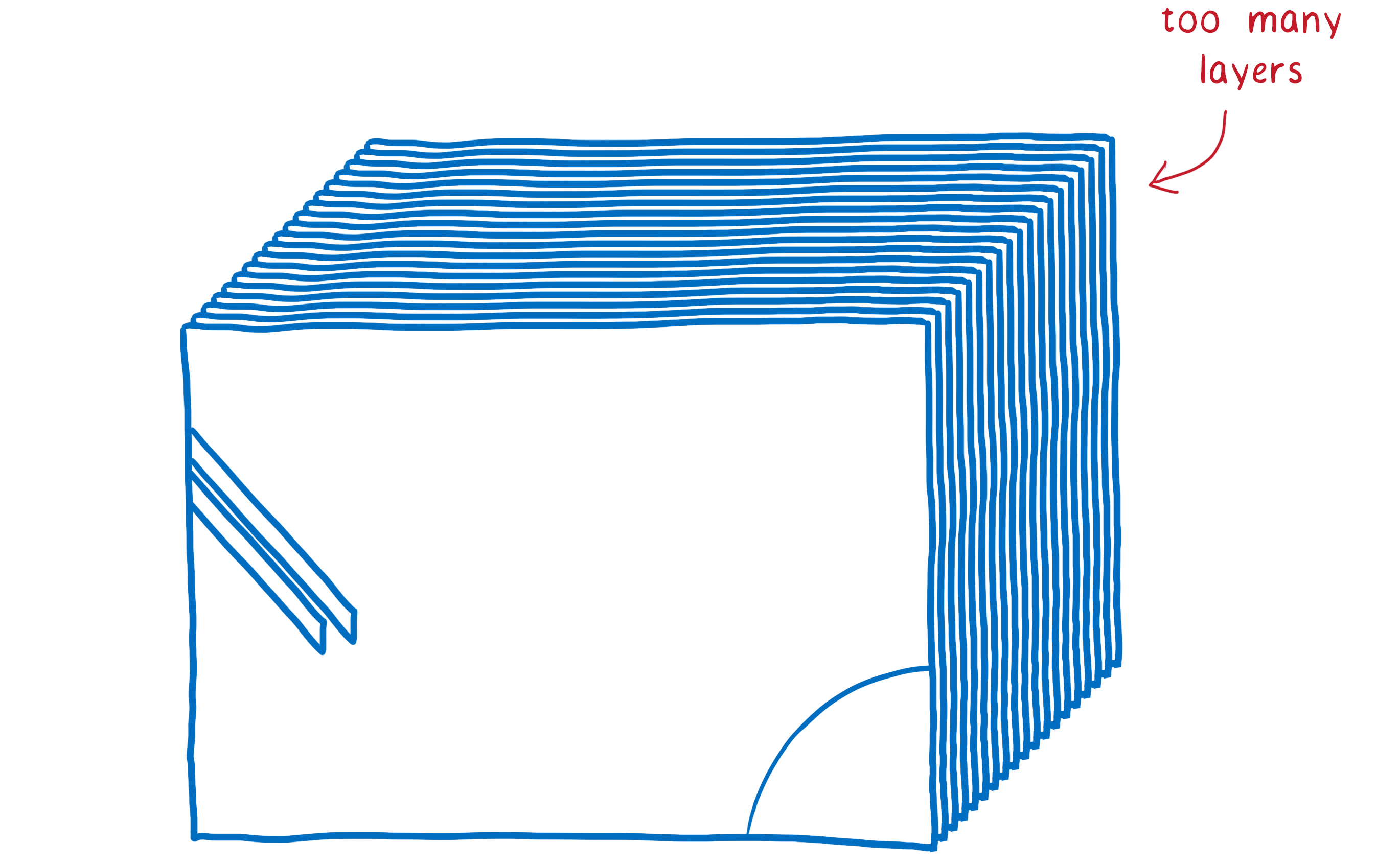
Dans d’autres cas, on peut avoir un seul calque là où il en aurait fallu plusieurs. Ainsi, ce calque sera sans cesse redessiné et transféré au compositeur qui ne se chargera que de l’afficher puisqu’il n’a rien à faire.
On a alors doublé le travail nécessaire pour le dessin puisque l’on touche chaque pixel deux fois sans aucun bénéfice. Afficher la page sans l’étape de composition aurait été plus rapide.

Dans de nombreux cas, les calques ne sont pas efficaces. Par exemple si vous animez la couleur de l’arrière-plan, le calque entier doit être redessiné. Les calques sont utiles pour un nombre restreint de propriétés CSS.
Même si la plupart des images sont des cas idéaux à gérer dans le sens où ils ne prennent pas beaucoup de temps sur l’intervalle entre deux images à afficher, vous pouvez avoir un rendu saccadé. Pour que ce soit perceptible, il suffit que quelques images soient extrêmement difficiles à rendre.

Ces cas sont appelés falaises de performance. Votre application se comporte pas trop mal, jusqu’à ce qu’elle heurte un de ces scénarios (comme l’animation de l’arrière-plan) et tout d’un coup le nombre d’images par seconde chute brutalement.
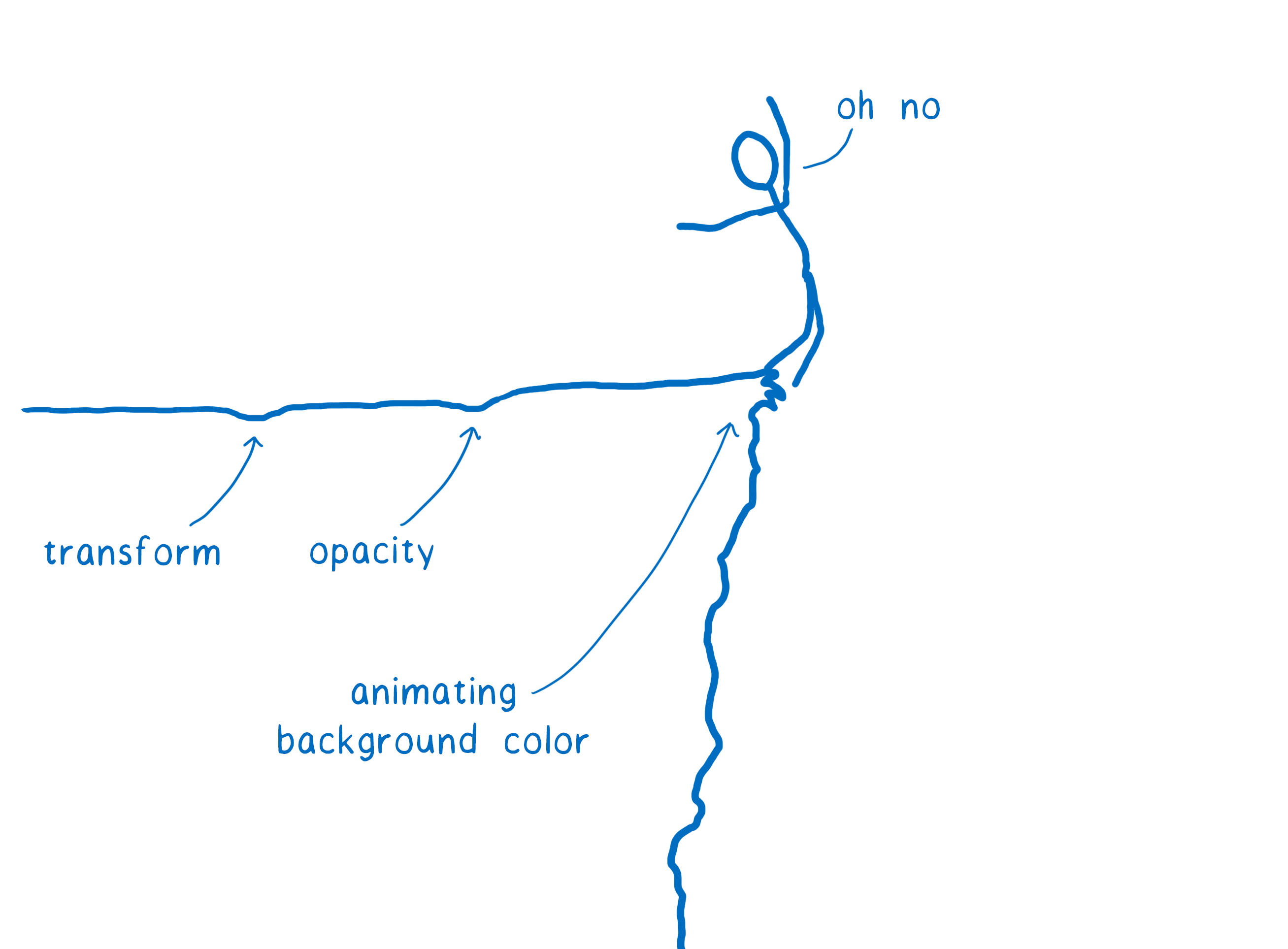
On peut se débarrasser de ces falaises.
Comment ? En s’inspirant des moteurs de jeux 3D.
Utiliser le processeur graphique comme un moteur de jeu
Et si on essayait d’arrêter de deviner ce qu’il faut pour les calques ? Et si on enlevait la frontière entre dessin et composition et qu’on reprenait au début en essayant tout simplement de rendre chaque pixel pour chaque image ?
Cela peut sembler ridicule, mais cela a déjà été tenté auparavant. Les jeux vidéo actuels rendent chaque pixel et maintiennent 60 images par seconde de façon plus stable que les navigateurs. Et ils le font d’une façon un peu surprenante… au lieu de créer des zones d’invalidation et des calques pour minimiser ce qu’il y a à rendre, ils calculent simplement l’ensemble de l’écran.
Effectuer le rendu d’une page web de cette manière ne serait-il pas beaucoup plus lent ?
Si on effectuait le rendu avec le processeur, ça serait plus lent. Mais les processeurs graphiques sont conçus pour que cela fonctionne.
Les processeurs graphiques sont conçus pour de la parallélisation extrême. J’ai déjà abordé la parallélisation dans mon dernier article sur Stylo. Avec la parallélisation, la carte peut effectuer plusieurs tâches à la fois. Le nombre d’activités en parallèle est uniquement limité par son nombre de cœurs.
Les processeurs ont généralement entre 2 et 8 cœurs. Les processeurs graphiques en possèdent au moins quelques centaines, la plupart intègrent plus de 1 000 cœurs.
Pour autant, ces cœurs fonctionnent différemment. Ils ne peuvent agir de façon totalement autonome comme le cœur d’un processeur. Au lieu de cela, ils travaillent ensemble, exécutant la même instruction sur plusieurs jeux de données.
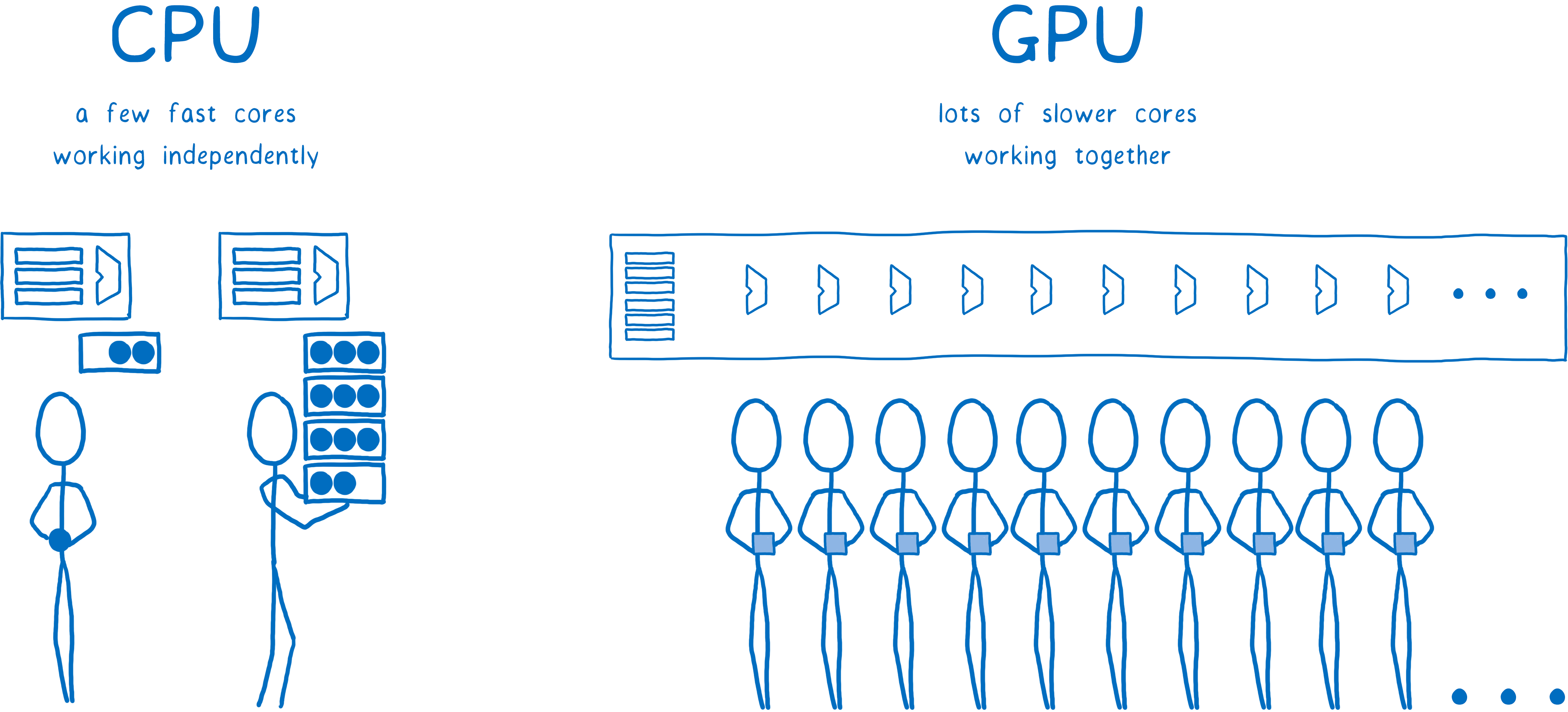
C’est exactement ce dont on a besoin lorsqu’il s’agit de remplir des pixels. Chaque pixel peut être rempli par un cœur différent. Par sa capacité à travailler sur des centaines de pixels à la fois, un processeur graphique est bien plus rapide qu’un processeur principal… enfin, tant que vous fournissez du travail à l’ensemble des cœurs.
Les cœurs ont besoin d’effectuer la même tâche en même temps, les processeurs graphiques ont une liste d’étapes précises à suivre et leurs API sont assez restrictives. Voyons cela en détail.
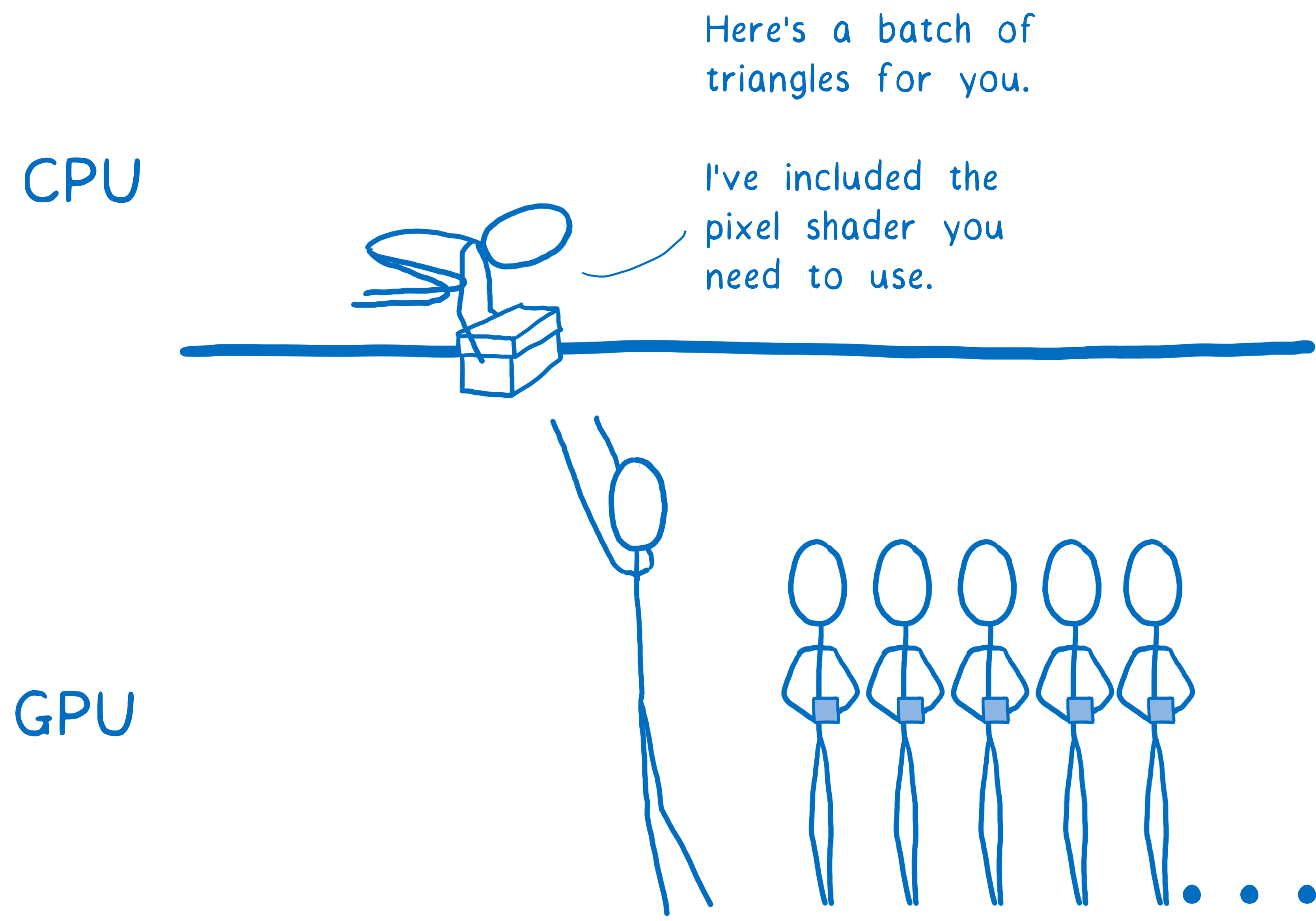
Il faut d’abord commencer par dire au processeur graphique ce qu’il doit dessiner. Autrement dit, lui donner des formes et lui dire comment les remplir.
Pour ce faire, il faut décomposer votre dessin en formes simples (généralement des triangles). Ces formes évoluent en 3D, donc certaines peuvent être au second plan. Ensuite, vous prenez les sommets de ces triangles et vous placez leurs coordonnées (x,y,z) dans un tableau.
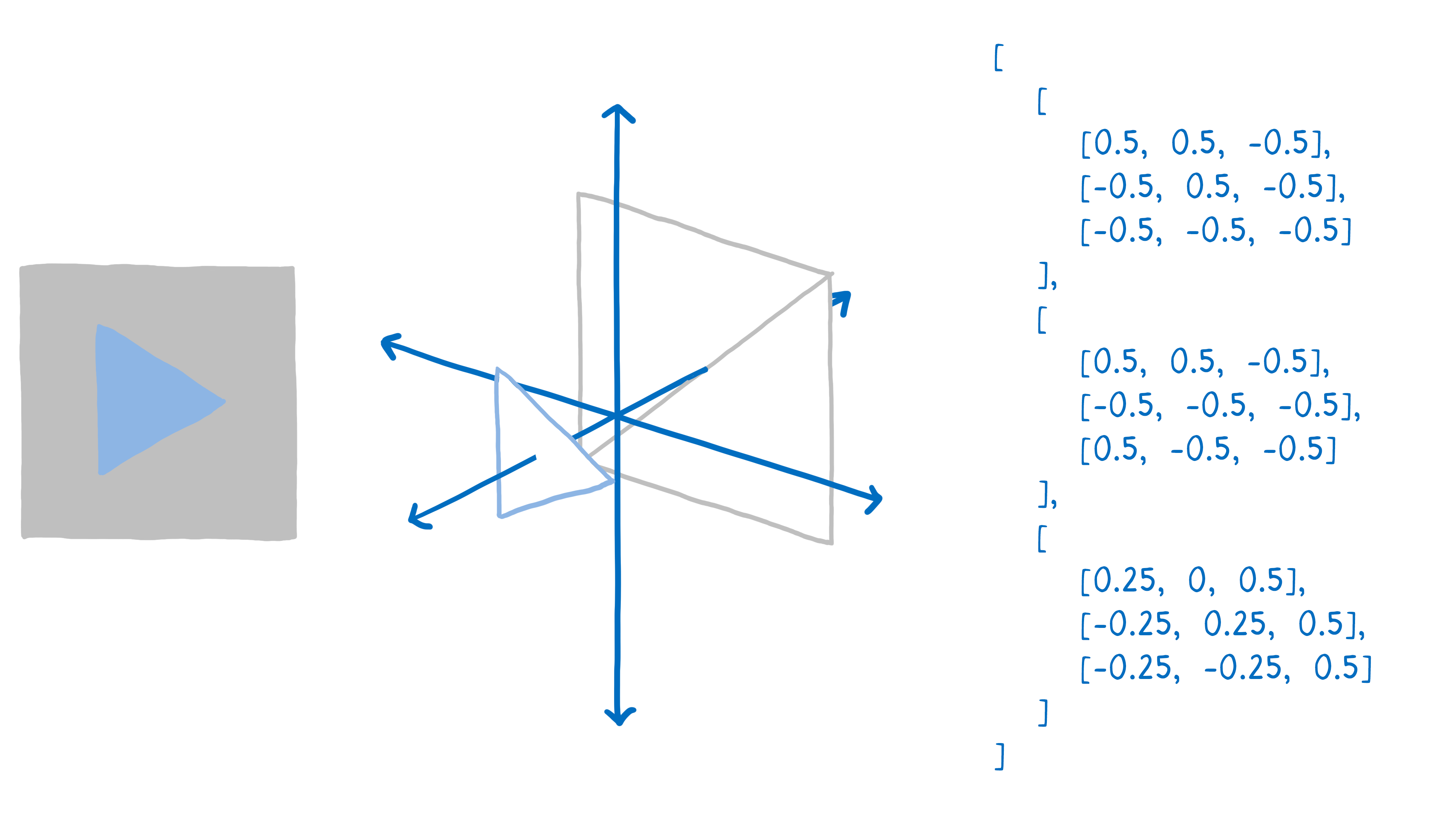
Ensuite, vous appelez le processeur graphique pour dessiner ces formes.
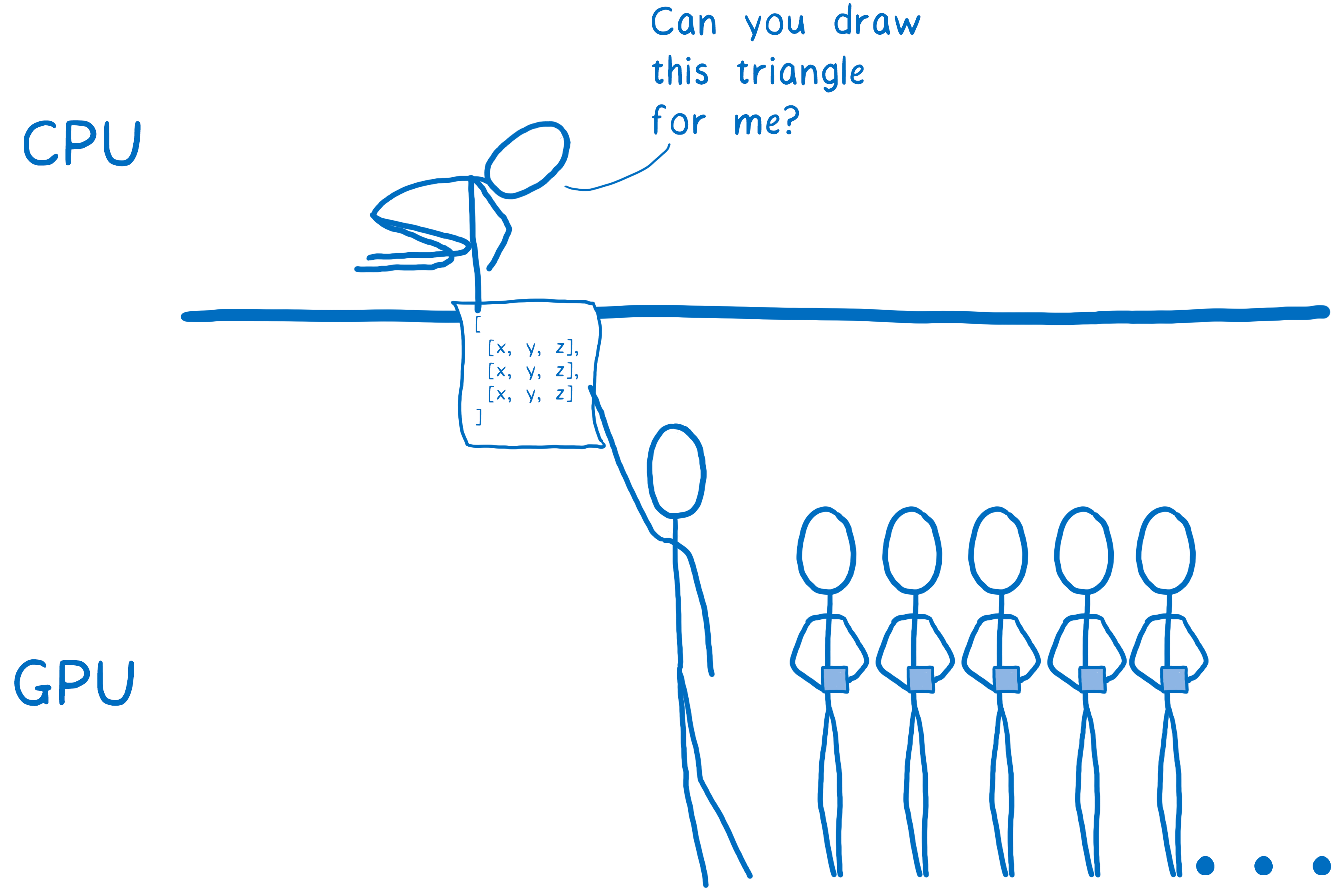
À partir de là, le processeur graphique se charge du reste. Tous les cœurs vont travailler de la même manière de façon synchronisée. Dans l’ordre :
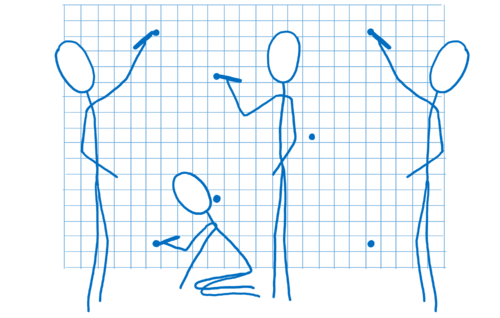
- Déterminer où se trouve l’ensemble des angles associés aux formes. C’est ce qu’on appelle le vertex shading (ou nuancement des sommets).
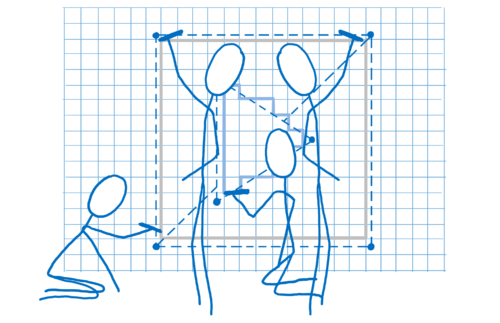
- Déterminer les segments qui lient ces sommets. Ce qui permet de savoir quels pixels sont couverts par ces formes. C’est la rastérisation.
- Maintenant que l’on sait quels pixels sont couverts par une forme, il faut parcourir chaque pixel de cette forme et déterminer de quelle couleur il devrait être. C’est l’étape de pixel shading (ou nuancement des pixels).
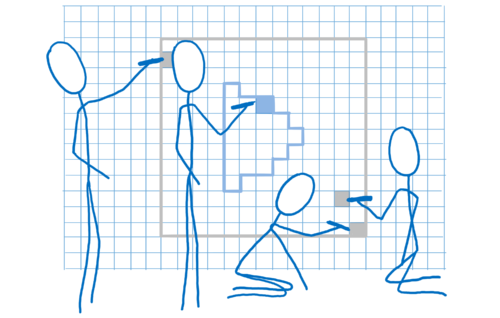
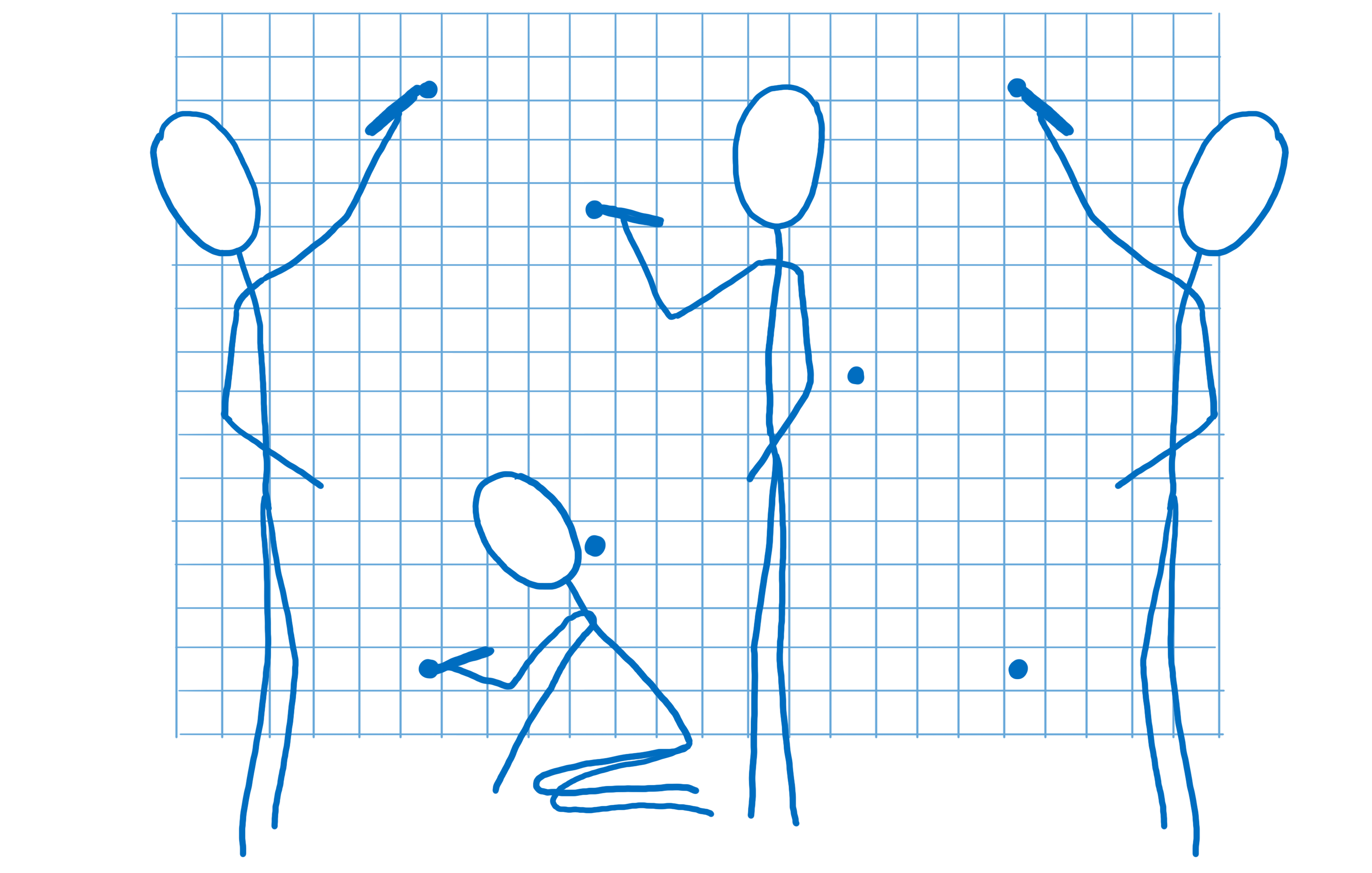
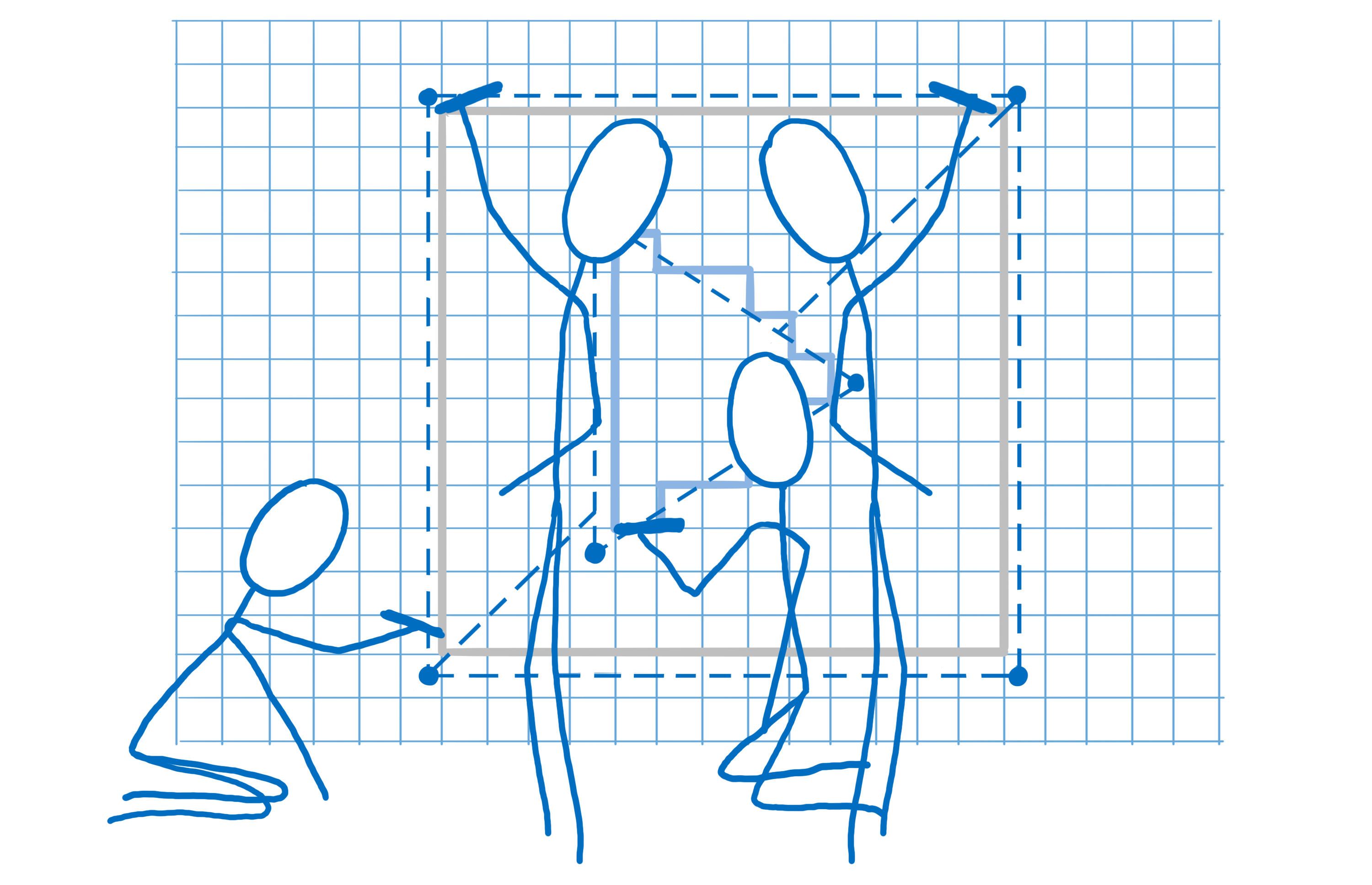
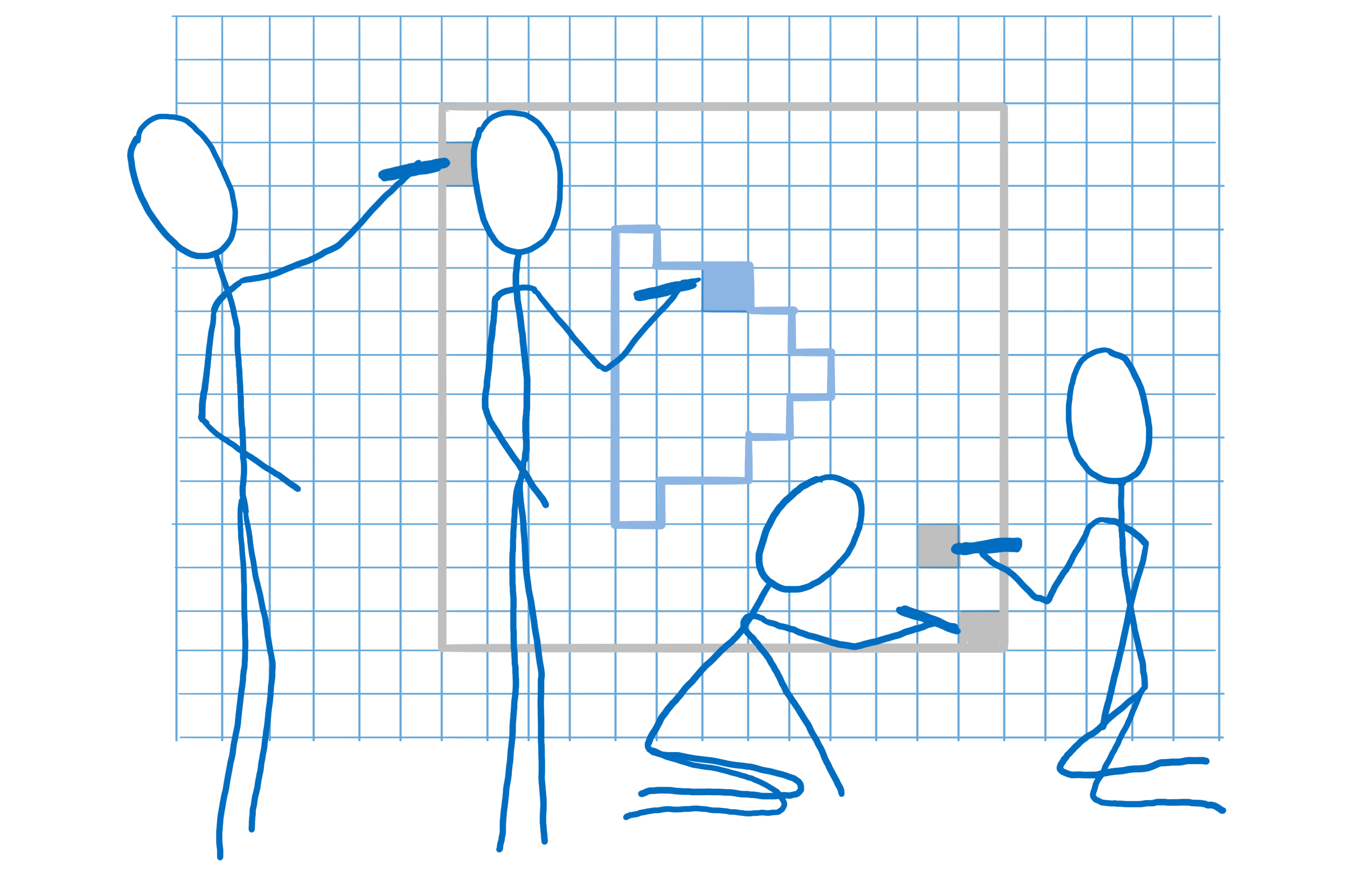
Cette dernière étape peut s’effectuer de différentes manières. Pour transmettre les instructions au processeur graphique, il faut lui fournir un programme appelé pixel shader (ou nuanceur). Le pixel shading est l’une des rares parties programmables du processeur graphique.
Certains pixel shaders sont simples, par exemple si une forme ne contient qu’une seule couleur, le shader (ou nuanceur) n’a besoin que de renvoyer cette couleur pour chaque pixel contenu dans la forme.
Parfois, c’est plus complexe, comme dans le cas d’une image en arrière-plan. Il faut déterminer quelle partie de l’image correspond à chaque pixel. On peut traiter le problème de la même manière que les artistes qui agrandissent ou rapetissent une image : en mettant une grille sur l’image où chaque carreau correspond à un pixel. Une fois que l’on sait quel carreau correspond à un pixel, on assemble les couleurs à l’intérieur du carreau pour trouver la couleur du pixel. On parle de texture mapping (ou cartographie de texture) puisque l’on associe l’image (appelée texture) aux pixels.

Le processeur graphique fera appel au pixel shader pour chaque pixel. Les cœurs travailleront sur des pixels différents en parallèle, mais ils doivent tous utiliser le même pixel shader. Lorsque vous demandez au processeur graphique de dessiner les formes, vous lui fournissez aussi le pixel shader à utiliser.
Pour la plupart des pages web, chaque partie de la page aura besoin d’un pixel shader spécifique.
Comme le shader s’applique à toutes les formes de l’appel de dessin, il faut souvent décomposer les appels de dessin en différents groupes. On parle alors de lots. Pour que les cœurs soient tout le temps occupés, vous devez créer un petit nombre de lots, chacun d’entre eux contenant beaucoup de formes.
Nous venons de voir comment le processeur graphique sépare le travail entre des centaines ou des milliers de cœurs. C’est uniquement grâce à cette parallélisation extrême que nous pouvons envisager de rendre l’ensemble de chaque image. D’autre part, malgré la parallélisation, la charge de travail reste élevée, il s’agit donc de le faire de manière intelligente. C’est là que WebRender entre en jeu…
Comment WebRender interagit avec le processeur graphique
Revenons sur la liste des étapes à accomplir pour servir une page. Il y a eu deux changements.

- Il n’y a plus de distinction entre le dessin et la composition. Ils font partie de la même étape. Le processeur graphique les exécute ensemble en fonction des commandes passées dans l’API.
- L’affichage fournit une structure différente de données à traiter. Il s’agissait auparavant d’un arbre d’images (frame tree) ou d’un arbre de rendu dans Chrome. Désormais, il fournit une liste d’affichage.
La liste d’affichage est un ensemble haut niveau d’instructions de dessin. Il décrit ce qu’il y a à dessiner sans être spécifique à une API graphique.
Dès qu’il y a quelque chose de nouveau à dessiner, le processus principal donne cette liste d’affichage au RenderBackend qui est le code du WebRender qui s’exécute sur le processeur.
Le travail du RenderBackend est de prendre cette liste d’instructions de haut niveau de dessin et de la convertir en appels compréhensibles par le processeur graphique, assemblés en lots pour qu’ils s’exécutent rapidement.

Ensuite, le RenderBackend passe ces lots au processus de composition qui les envoie vers le processeur graphique.
Le RenderBackend a pour objectif de construire les appels de dessin qu’il donne le plus rapidement possible au processeur graphique. Il utilise différentes techniques pour cela.
Supprimer les formes inutiles de la liste (élimination précoce)
La meilleure manière pour gagner du temps est de ne pas avoir de travail à effectuer.
En premier lieu, le RenderBackend épure la liste des éléments. Il détermine quels éléments seront véritablement affichés à l’écran. Pour cela, il se base sur certaines informations comme le taille maximale qu’il est possible d’afficher lors du défilement.
Si une forme rentre dans la zone d’affichage, elle alors est incluse dans la liste. Si aucun élément de la forme n’est dans cette zone, elle est retirée de la liste. Ce processus est appelé l’élimination précoce (early culling).

Minimiser le nombre de textures intermédiaires (l’arbre de tâches du moteur de rendu)
Nous avons désormais un arbre de l’ensemble des formes que nous allons utiliser. Cet arbre est organisé en empilement de contextes comme nous l’avons vu plus haut.
Les effets comme les filtres CSS sur les empilements de contextes rendent les choses un petit peu compliquées. Par exemple si vous avez un élément qui a une opacité de 0,5 et qu’il possède des enfants. On pourrait penser que chaque enfant est transparent mais en fait la transparence s’applique au niveau du groupe.

Cela nous oblige à rendre le groupe comme une texture opaque puis, avec l’aide du parent, modifier l’opacité de l’ensemble de la texture.
Ces empilements peuvent être imbriqués et le parent peut tout aussi bien faire partie d’un autre contexte, on doit alors à nouveau rendre une texture intermédiaire et ainsi de suite.
Créer l’espace pour ces textures est coûteux. On préférera, si possible, grouper l’ensemble au sein d’une texture intermédiaire unique.
Pour aider le processeur graphique à y arriver, on crée un arbre de tâches pour le rendu. Grâce à cet arbre, nous pouvons déterminer l’ordre de création des textures. Toutes les textures indépendantes peuvent être créées directement et groupées au sein de la même texture intermédiaire.
Dans l’exemple ci-dessus, nous avons fait une première passe pour afficher l’ombre d’un coin (c’est un tantinet plus complexe, mais c’est l’idée).
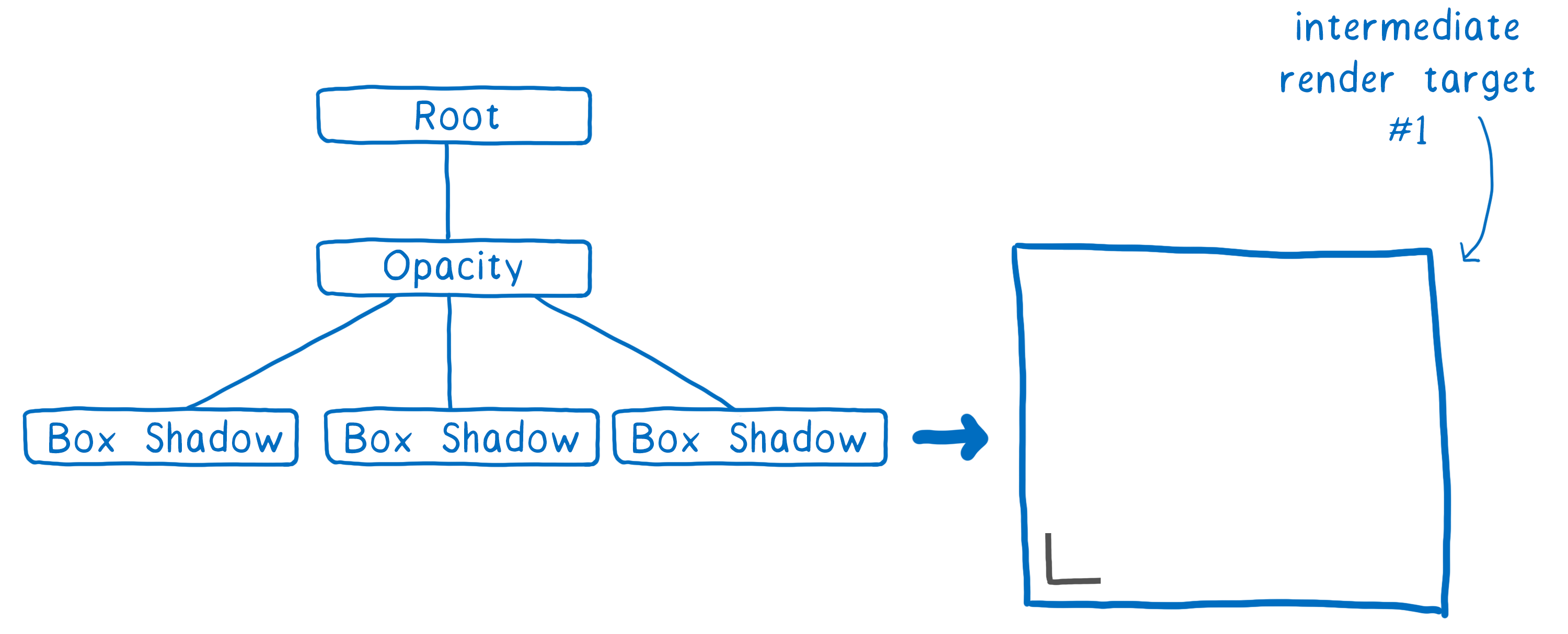
Dans une deuxième passe nous pouvons dupliquer ce coin tout autour de la boîte pour placer l’ombre associée. On rend ensuite le groupe avec une opacité totale.
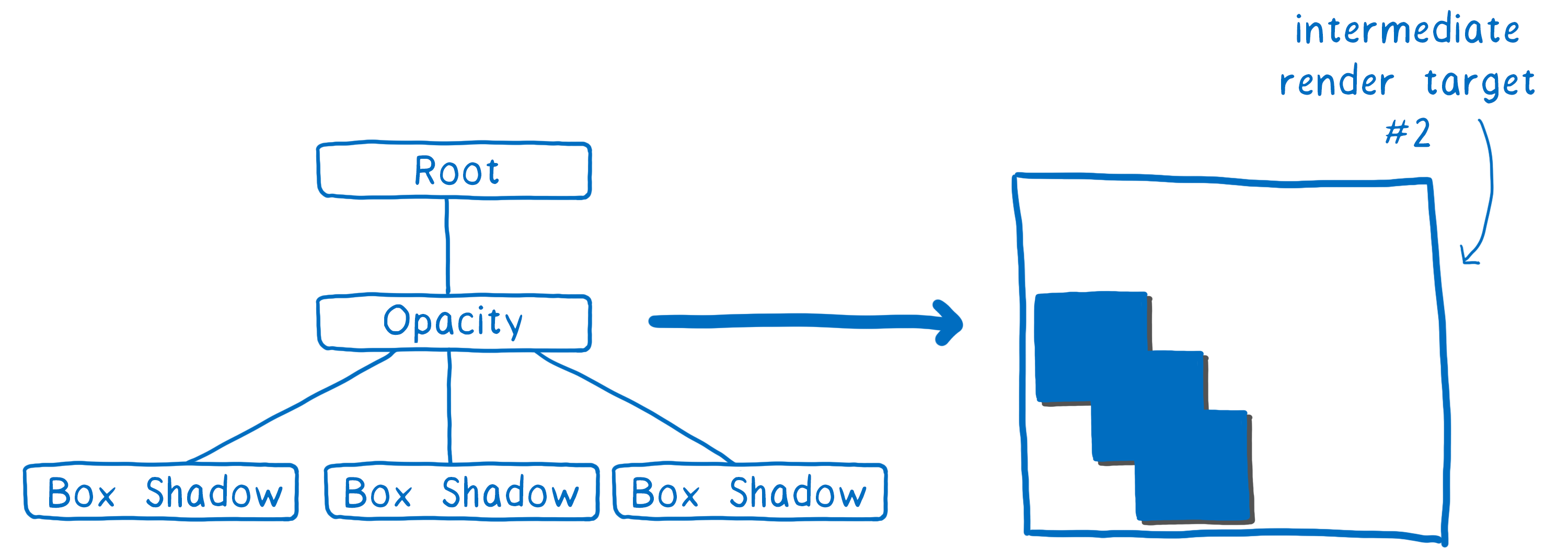
Ensuite, tout ce qu’il reste à faire est de modifier l’opacité de cette texture et on la place là où elle doit aller dans la texture finale qui sera celle affichée à l’écran.
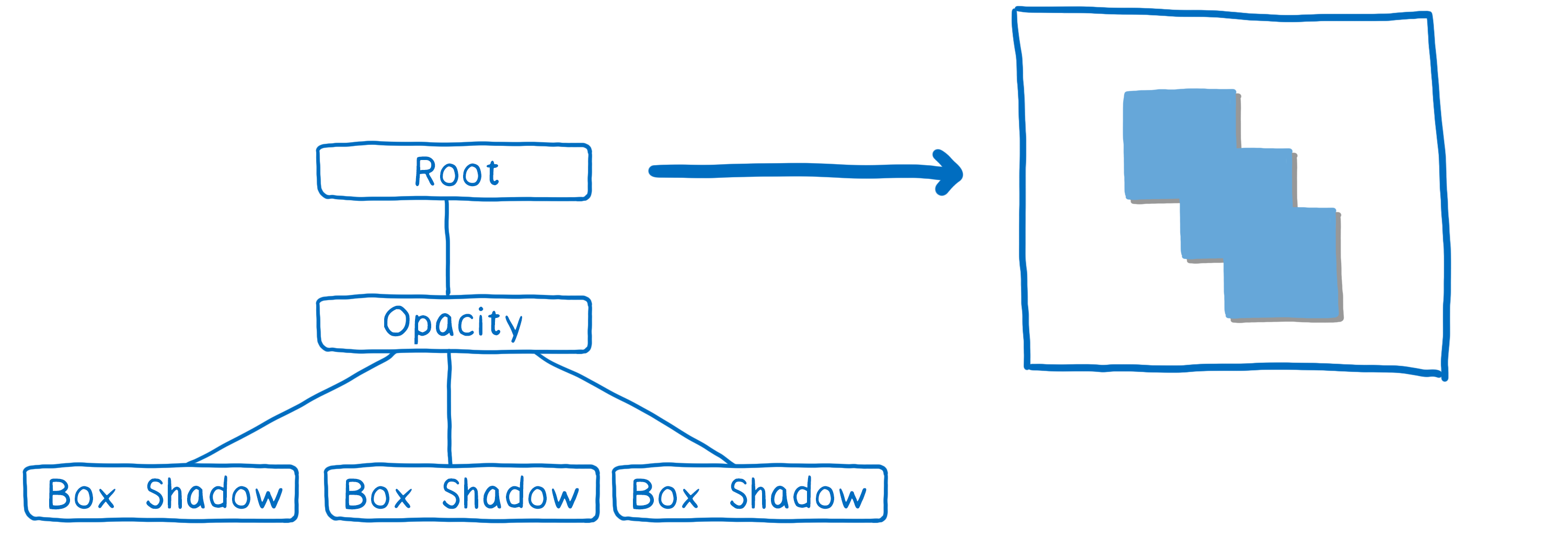
En construisant cet arbre de tâches, nous pouvons connaître le nombre minimal de textures à utiliser. Ce qui n’est pas plus mal, puisque, comme je l’ai mentionné avant, créer l’espace nécessaire au rendu de ces textures est coûteux.
Cela nous permet aussi de lotir les choses entre elles.
Regrouper les appels de dessin (lotissement)
Comme nous l’avons mentionné avant, nous avons besoin d’un petit nombre de lots contenant beaucoup de formes.
Faire attention à la manière dont on crée ces lots peut vraiment faire la différence. Il nous faut vraiment le plus de formes possibles dans un lot et ce pour plusieurs raisons.
Tout d’abord, lorsque le processeur transmet un appel au processeur graphique, la charge du processeur principal augmente considérablement. Il doit gérer la configuration du processeur graphique, transmettre le programme du nuanceur et tester différents problèmes matériels éventuels. Toutes ces tâches s’additionnent et, pendant que le processeur travail, il se peut que le processeur graphique se tourne les pouces.
Ensuite, changer d’état à un coût. Prenons le cas où il est nécessaire de changer le programme de nuanceur entre deux lots. Sur un processeur graphique générique, il faut attendre que l’ensemble des cœurs aient fini d’utiliser le nuanceur actuel. On parle de vider le pipeline graphique. En attendant que le pipeline se vide, les autres cœurs sont à l’arrêt.

Pour ces raisons, il est nécessaire de grouper les lots au maximum. Pour un ordinateur de bureau standard, l’ordre de grandeur acceptable est de 100 appels ou moins par image et chaque appel doit contenir plusieurs milliers de sommets. De cette manière, on tire le meilleur parti de la parallélisation.
De notre côté, on regarde chaque passe de l’arbre de tâches et on essaie de voir ce que l’on peut grouper.
Pour le moment, chaque élément primitif nécessite un nuanceur différent. Par exemple, un nuanceur pour les bordures, un pour les textes et un pour les images.
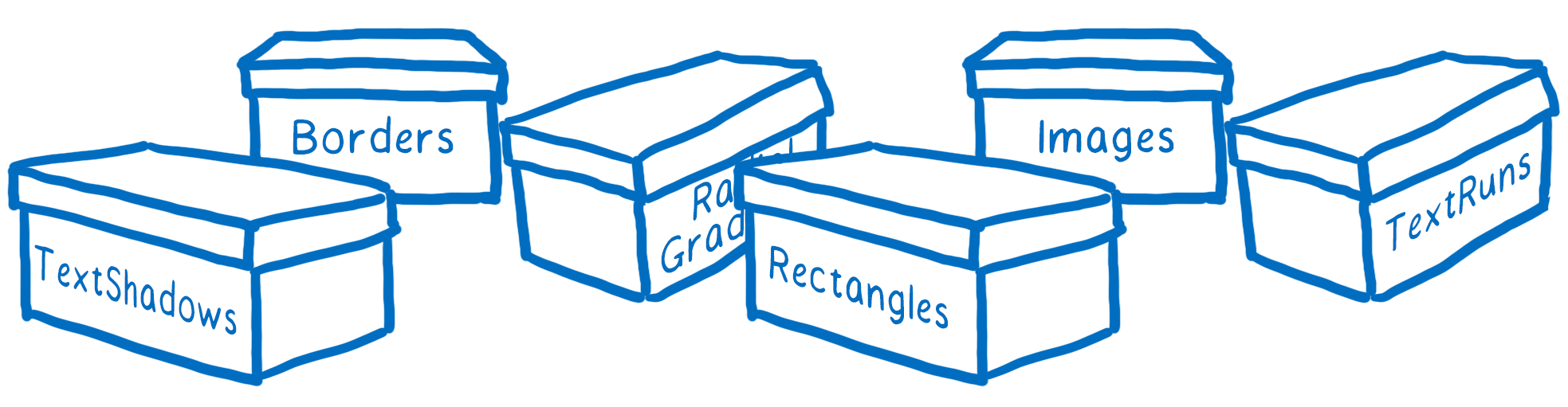
Nous pensons être en mesure de combiner plusieurs de ces nuanceurs, ce qui nous permettrait d’avoir des lots encore plus gros, mais on s’en sort déjà pas trop mal.
Il ne nous reste pas grand chose avant d’envoyer tout cela au processeur graphique. Et si on pouvait encore enlever un peu de travail inutile ?
Réduction des superpositions avec les passes opaque et alpha (élimination selon l’axe Z)
La plupart des pages web ont des formes qui vont se superposer. Par exemple, une zone de texte se situe au-dessus d’un div (avec une couleur) qui est au-dessus d’un body (d’une autre couleur).
Lorsqu’il détermine de quelle couleur doit être un pixel, le processeur graphique pourrait déterminer la couleur du pixel pour chaque forme. Le problème, c’est que seule la forme du dessus sera affichée. On génère de la surimpression et on consomme du temps de calcul sur le processeur graphique pour rien.

Du coup, on pourrait effectuer le rendu de la forme du dessus en premier. Pour la forme en dessous, si on a déjà le pixel de rempli, alors on ne fait rien.

Cette approche génère néanmoins un léger problème. Lorsqu’une forme est translucide, vous avez besoin de combiner la couleur de cette forme avec celle du dessous. Pour que cela forme un rendu cohérent, il est nécessaire de le faire en partant du fond pour arriver à la couche supérieure.
On sépare donc le travail en deux passes. On commence par la passe opaque, on va de haut en bas et on effectue le rendu des formes opaques. On ignore les pixels qui seraient derrière d’autres pixels.
On se charge ensuite des formes translucides. On parcourt la pile de bas en haut. Si un pixel translucide est au-dessus d’un pixel opaque, on le fusionne avec le pixel opaque. S’il est derrière un pixel opaque, on ne le calcule pas.
Ce processus qui sépare le travail entre la passe opaque et la passe alpha pour ensuite ignorer les pixels inutiles constitue l’élimination selon l’axe Z (Z-culling).
Ça peut sembler comme une optimisation légère mais ça nous a permis de gagner énormément de performances. Sur une page web usuelle, cela réduit énormément le nombre de pixels à considérer et nous essayons de faire encore plus de travail avec l’aide de la passe opaque.
À cette étape, nous avons préparé l’image. On a fait tout ce qu’on a pu pour réduire le travail.
… Et nous sommes prêts à dessiner !
Nous sommes prêts à configurer le processeur graphique et effectuer le rendu des lots.

Une remarque : tout ne s’effectue pas encore dans le processeur graphique
Le processeur doit encore effectuer une partie de l’affichage. Ainsi, nous effectuons toujours le rendu des caractères (glyphes) qui sont utilisés dans des blocs de texte à l’aide du processeur. On pourrait envisager de le faire à l’aide de le processeur graphique, mais il est difficile d’obtenir une correspondance pixel par pixel avec les glyphes que l’ordinateur restitue dans les autres applications et, de ce fait, les fontes rendues à l’aide du processeur graphique pourraient désorienter les utilisateurs. Nous essayons de migrer le rendu des glyphes vers le processeur graphique à l’aide du projet Pathfinder.
Pour le moment, ces éléments sont dessinés dans des images par le processeur puis sont transférés dans le cache texture du processeur graphique. Ce cache est conservé entre les images puisque les glyphes ne changent pas a priori.
Même si le rendu s’effectue toujours sur le processeur, nous pouvons le rendre plus rapide. Ainsi lorsque l’on effectue le rendu des caractères d’une police d’écriture, on divise le travail entre les différents cœurs. On se sert de la même technique utilisée par Stylo pour paralléliser le calcul du style… le vol de travail.
Quelles sont les prochaines étapes pour WebRender ?
Nous attendons beaucoup de l’arrivée de WebRender dans Firefox au sein de Quantum Render en 2018, quelques versions après la première de Firefox Quantum. Cela permettra un rendu plus fluide des pages actuelles. Nous préparons aussi Firefox à la génération à venir d’écrans 4K, la performance du rendu devenant critique lorsque le nombre de pixels sur un écran augmente.
Mais, WebRender ne sert pas uniquement à Firefox. Il est aussi critique dans les travaux autour de WebVR où il faut effectuer le rendu de deux écrans différents pour chaque œil, à 90 images par seconde, le tout en 4K.
Une première version de WebRender est actuellement disponible derrière un élément de configuration de Firefox. L’intégration est en cours, ce qui signifie que les performances ne sont pas aussi bonnes que lorsque ce sera fini. Si vous souhaitez suivre le développement de WebRender, vous pouvez vous abonner au dépôt GitHub ou suivre Firefox Nightly sur Twitter pour des actualités hebdomadaires sur l’ensemble du projet Quantum Render.
À propos de Lin Clark
Lin est ingénieure dans l’équipe Mozilla Developer Relations. Elle bricole autour de JavaScript, WebAssembly, Rust et Servo et dessine également des esquisses de code.
(*) L’article a été publié le 10 octobre 2017, plus d’un mois avant la sortie de Firefox Quantum.
Aller plus loin
Projet Quantum
Entrez dans l’ère Quantum – comment Firefox est redevenu rapide et comment il va devenir plus rapide encore – 13 nov. 2017 – Lin Clark traduite
Au cœur d’un moteur CSS super rapide : Quantum CSS – 2 sept. 2017 – Lin Clark traduite
Remplacer le moteur de l’avion en plein vol – 4 janv. 2017 – Jen Simmons traduite
Quantum va vous faire réaimer Firefox et le Web – 30 oct. 2016
Un saut quantique pour le Web – 27 oct. 2016 – David Bryant traduit
Le projet Quantum de Mozilla, des ambitions et des précisions – 27 oct. 2016 – Bill Mc Closkey traduit
De Lin Clark
Une introduction cartoonesque à WebAssembly – 28 fév. 2017 – Lin Clark traduite
Un petit cours accéléré de compilation à la volée (JIT) – 28 fév. 2017 – Lin Clark traduite
Créer et manipuler des modules WebAssembly – 28 fév. 2017 – Lin Clark traduite
D’où vient la rapidité de WebAssembly ? – 28 fév. 2017 – Lin Clark traduite
WebAssembly aujourd’hui et demain – 28 fév. 2017 – Lin Clark traduite
Traduction et relecture : Mozinet, Marine, Alpha, nico@nc, Goofy, Hellosct1 et anonymes
Précédent article sur le futur de Firefox : Entrez dans l’ère Quantum – comment Firefox est redevenu rapide et comment il va devenir plus rapide encore
Crédit illustrations : Lin Clark.